Feature Detection¶
Canny¶
- void cvCanny(const CvArr* image, CvArr* edges, double threshold1, double threshold2, int aperture_size=3)¶
Implements the Canny algorithm for edge detection.
Parameters: - image – Single-channel input image
- edges – Single-channel image to store the edges found by the function
- threshold1 – The first threshold
- threshold2 – The second threshold
- aperture_size – Aperture parameter for the Sobel operator (see Sobel )
The function finds the edges on the input image image and marks them in the output image edges using the Canny algorithm. The smallest value between threshold1 and threshold2 is used for edge linking, the largest value is used to find the initial segments of strong edges.
CornerEigenValsAndVecs¶
- void cvCornerEigenValsAndVecs(const CvArr* image, CvArr* eigenvv, int blockSize, int aperture_size=3)¶
Calculates eigenvalues and eigenvectors of image blocks for corner detection.
Parameters: - image – Input image
- eigenvv – Image to store the results. It must be 6 times wider than the input image
- blockSize – Neighborhood size (see discussion)
- aperture_size – Aperture parameter for the Sobel operator (see Sobel )
For every pixel, the function
cvCornerEigenValsAndVecs
considers a
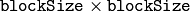 neigborhood S(p). It calcualtes the covariation matrix of derivatives over the neigborhood as:
neigborhood S(p). It calcualtes the covariation matrix of derivatives over the neigborhood as:
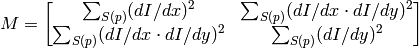
After that it finds eigenvectors and eigenvalues of the matrix and stores them into destination image in form
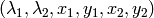 where
where
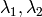
are the eigenvalues of
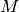 ; not sorted
; not sorted
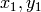
are the eigenvectors corresponding to
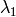
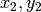
are the eigenvectors corresponding to
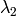
CornerHarris¶
- void cvCornerHarris(const CvArr* image, CvArr* harris_dst, int blockSize, int aperture_size=3, double k=0.04)¶
Harris edge detector.
Parameters: - image – Input image
- harris_dst – Image to store the Harris detector responses. Should have the same size as image
- blockSize – Neighborhood size (see the discussion of CornerEigenValsAndVecs )
- aperture_size – Aperture parameter for the Sobel operator (see Sobel ).
- k – Harris detector free parameter. See the formula below
The function runs the Harris edge detector on the image. Similarly to
CornerMinEigenVal
and
CornerEigenValsAndVecs
, for each pixel it calculates a
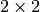 gradient covariation matrix
over a
neighborhood. Then, it stores
gradient covariation matrix
over a
neighborhood. Then, it stores
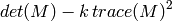
to the destination image. Corners in the image can be found as the local maxima of the destination image.
CornerMinEigenVal¶
- void cvCornerMinEigenVal(const CvArr* image, CvArr* eigenval, int blockSize, int aperture_size=3)¶
Calculates the minimal eigenvalue of gradient matrices for corner detection.
Parameters: - image – Input image
- eigenval – Image to store the minimal eigenvalues. Should have the same size as image
- blockSize – Neighborhood size (see the discussion of CornerEigenValsAndVecs )
- aperture_size – Aperture parameter for the Sobel operator (see Sobel ).
The function is similar to
CornerEigenValsAndVecs
but it calculates and stores only the minimal eigen value of derivative covariation matrix for every pixel, i.e.
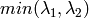 in terms of the previous function.
in terms of the previous function.
ExtractSURF¶
- void cvExtractSURF(const CvArr* image, const CvArr* mask, CvSeq** keypoints, CvSeq** descriptors, CvMemStorage* storage, CvSURFParams params)¶
Extracts Speeded Up Robust Features from an image.
Parameters: - image – The input 8-bit grayscale image
- mask – The optional input 8-bit mask. The features are only found in the areas that contain more than 50 % of non-zero mask pixels
- keypoints – The output parameter; double pointer to the sequence of keypoints. The sequence of CvSURFPoint structures is as follows:
typedef struct CvSURFPoint { CvPoint2D32f pt; // position of the feature within the image int laplacian; // -1, 0 or +1. sign of the laplacian at the point. // can be used to speedup feature comparison // (normally features with laplacians of different // signs can not match) int size; // size of the feature float dir; // orientation of the feature: 0..360 degrees float hessian; // value of the hessian (can be used to // approximately estimate the feature strengths; // see also params.hessianThreshold) } CvSURFPoint;
Parameters: - descriptors – The optional output parameter; double pointer to the sequence of descriptors. Depending on the params.extended value, each element of the sequence will be either a 64-element or a 128-element floating-point ( CV_32F ) vector. If the parameter is NULL, the descriptors are not computed
- storage – Memory storage where keypoints and descriptors will be stored
- params – Various algorithm parameters put to the structure CvSURFParams:
typedef struct CvSURFParams { int extended; // 0 means basic descriptors (64 elements each), // 1 means extended descriptors (128 elements each) double hessianThreshold; // only features with keypoint.hessian // larger than that are extracted. // good default value is ~300-500 (can depend on the // average local contrast and sharpness of the image). // user can further filter out some features based on // their hessian values and other characteristics. int nOctaves; // the number of octaves to be used for extraction. // With each next octave the feature size is doubled // (3 by default) int nOctaveLayers; // The number of layers within each octave // (4 by default) } CvSURFParams; CvSURFParams cvSURFParams(double hessianThreshold, int extended=0); // returns default parameters
The function cvExtractSURF finds robust features in the image, as described in [Bay06] . For each feature it returns its location, size, orientation and optionally the descriptor, basic or extended. The function can be used for object tracking and localization, image stitching etc.
See the find_obj.cpp demo in OpenCV samples directory.
FindCornerSubPix¶
- void cvFindCornerSubPix(const CvArr* image, CvPoint2D32f* corners, int count, CvSize win, CvSize zero_zone, CvTermCriteria criteria)¶
Refines the corner locations.
Parameters: - image – Input image
- corners – Initial coordinates of the input corners; refined coordinates on output
- count – Number of corners
- win – Half of the side length of the search window. For example, if win =(5,5), then a
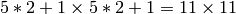 search window would be used
search window would be used - zero_zone – Half of the size of the dead region in the middle of the search zone over which the summation in the formula below is not done. It is used sometimes to avoid possible singularities of the autocorrelation matrix. The value of (-1,-1) indicates that there is no such size
- criteria – Criteria for termination of the iterative process of corner refinement. That is, the process of corner position refinement stops either after a certain number of iterations or when a required accuracy is achieved. The criteria may specify either of or both the maximum number of iteration and the required accuracy
The function iterates to find the sub-pixel accurate location of corners, or radial saddle points, as shown in on the picture below.
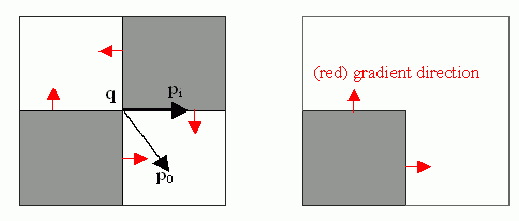
Sub-pixel accurate corner locator is based on the observation that every vector from the center
 to a point
to a point
 located within a neighborhood of
is orthogonal to the image gradient at
subject to image and measurement noise. Consider the expression:
located within a neighborhood of
is orthogonal to the image gradient at
subject to image and measurement noise. Consider the expression:
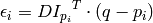
where
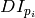 is the image gradient at the one of the points
is the image gradient at the one of the points
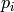 in a neighborhood of
. The value of
is to be found such that
in a neighborhood of
. The value of
is to be found such that
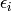 is minimized. A system of equations may be set up with
set to zero:
is minimized. A system of equations may be set up with
set to zero:
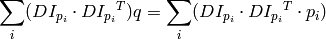
where the gradients are summed within a neighborhood (“search window”) of
. Calling the first gradient term
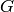 and the second gradient term
and the second gradient term
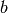 gives:
gives:
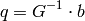
The algorithm sets the center of the neighborhood window at this new center
and then iterates until the center keeps within a set threshold.
GetStarKeypoints¶
- CvSeq* cvGetStarKeypoints(const CvArr* image, CvMemStorage* storage, CvStarDetectorParams params=cvStarDetectorParams())¶
Retrieves keypoints using the StarDetector algorithm.
Parameters: - image – The input 8-bit grayscale image
- storage – Memory storage where the keypoints will be stored
- params – Various algorithm parameters given to the structure CvStarDetectorParams:
typedef struct CvStarDetectorParams { int maxSize; // maximal size of the features detected. The following // values of the parameter are supported: // 4, 6, 8, 11, 12, 16, 22, 23, 32, 45, 46, 64, 90, 128 int responseThreshold; // threshold for the approximatd laplacian, // used to eliminate weak features int lineThresholdProjected; // another threshold for laplacian to // eliminate edges int lineThresholdBinarized; // another threshold for the feature // scale to eliminate edges int suppressNonmaxSize; // linear size of a pixel neighborhood // for non-maxima suppression } CvStarDetectorParams;
The function GetStarKeypoints extracts keypoints that are local scale-space extremas. The scale-space is constructed by computing approximate values of laplacians with different sigma’s at each pixel. Instead of using pyramids, a popular approach to save computing time, all of the laplacians are computed at each pixel of the original high-resolution image. But each approximate laplacian value is computed in O(1) time regardless of the sigma, thanks to the use of integral images. The algorithm is based on the paper Agrawal08 , but instead of a square, hexagon or octagon it uses an 8-end star shape, hence the name, consisting of overlapping upright and tilted squares.
Each computed feature is represented by the following structure:
typedef struct CvStarKeypoint
{
CvPoint pt; // coordinates of the feature
int size; // feature size, see CvStarDetectorParams::maxSize
float response; // the approximated laplacian value at that point.
}
CvStarKeypoint;
inline CvStarKeypoint cvStarKeypoint(CvPoint pt, int size, float response);
Below is the small usage sample:
#include "cv.h"
#include "highgui.h"
int main(int argc, char** argv)
{
const char* filename = argc > 1 ? argv[1] : "lena.jpg";
IplImage* img = cvLoadImage( filename, 0 ), *cimg;
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* keypoints = 0;
int i;
if( !img )
return 0;
cvNamedWindow( "image", 1 );
cvShowImage( "image", img );
cvNamedWindow( "features", 1 );
cimg = cvCreateImage( cvGetSize(img), 8, 3 );
cvCvtColor( img, cimg, CV_GRAY2BGR );
keypoints = cvGetStarKeypoints( img, storage, cvStarDetectorParams(45) );
for( i = 0; i < (keypoints ? keypoints->total : 0); i++ )
{
CvStarKeypoint kpt = *(CvStarKeypoint*)cvGetSeqElem(keypoints, i);
int r = kpt.size/2;
cvCircle( cimg, kpt.pt, r, CV_RGB(0,255,0));
cvLine( cimg, cvPoint(kpt.pt.x + r, kpt.pt.y + r),
cvPoint(kpt.pt.x - r, kpt.pt.y - r), CV_RGB(0,255,0));
cvLine( cimg, cvPoint(kpt.pt.x - r, kpt.pt.y + r),
cvPoint(kpt.pt.x + r, kpt.pt.y - r), CV_RGB(0,255,0));
}
cvShowImage( "features", cimg );
cvWaitKey();
}
GoodFeaturesToTrack¶
- void cvGoodFeaturesToTrack(const CvArr* image CvArr* eigImage, CvArr* tempImage CvPoint2D32f* corners int* cornerCount double qualityLevel double minDistance const CvArr* mask=NULL int blockSize=3 int useHarris=0 double k=0.04)¶
Determines strong corners on an image.
Parameters: - image – The source 8-bit or floating-point 32-bit, single-channel image
- eigImage – Temporary floating-point 32-bit image, the same size as image
- tempImage – Another temporary image, the same size and format as eigImage
- corners – Output parameter; detected corners
- cornerCount – Output parameter; number of detected corners
- qualityLevel – Multiplier for the max/min eigenvalue; specifies the minimal accepted quality of image corners
- minDistance – Limit, specifying the minimum possible distance between the returned corners; Euclidian distance is used
- mask – Region of interest. The function selects points either in the specified region or in the whole image if the mask is NULL
- blockSize – Size of the averaging block, passed to the underlying CornerMinEigenVal or CornerHarris used by the function
- useHarris – If nonzero, Harris operator ( CornerHarris ) is used instead of default CornerMinEigenVal
- k – Free parameter of Harris detector; used only if (
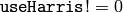 )
)
The function finds the corners with big eigenvalues in the image. The function first calculates the minimal
eigenvalue for every source image pixel using the
CornerMinEigenVal
function and stores them in
eigImage
. Then it performs
non-maxima suppression (only the local maxima in
 neighborhood
are retained). The next step rejects the corners with the minimal
eigenvalue less than
neighborhood
are retained). The next step rejects the corners with the minimal
eigenvalue less than
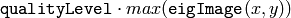 .
Finally, the function ensures that the distance between any two corners is not smaller than
minDistance
. The weaker corners (with a smaller min eigenvalue) that are too close to the stronger corners are rejected.
.
Finally, the function ensures that the distance between any two corners is not smaller than
minDistance
. The weaker corners (with a smaller min eigenvalue) that are too close to the stronger corners are rejected.
Note that the if the function is called with different values A and B of the parameter qualityLevel , and A > {B}, the array of returned corners with qualityLevel=A will be the prefix of the output corners array with qualityLevel=B .
HoughLines2¶
- CvSeq* cvHoughLines2(CvArr* image, void* storage, int method, double rho, double theta, int threshold, double param1=0, double param2=0)¶
Finds lines in a binary image using a Hough transform.
Parameters: - image – The 8-bit, single-channel, binary source image. In the case of a probabilistic method, the image is modified by the function
- storage – The storage for the lines that are detected. It can be a memory storage (in this case a sequence of lines is created in the storage and returned by the function) or single row/single column matrix (CvMat*) of a particular type (see below) to which the lines’ parameters are written. The matrix header is modified by the function so its cols or rows will contain the number of lines detected. If storage is a matrix and the actual number of lines exceeds the matrix size, the maximum possible number of lines is returned (in the case of standard hough transform the lines are sorted by the accumulator value)
- method –
The Hough transform variant, one of the following:
- CV_HOUGH_STANDARD classical or standard Hough transform. Every line is represented by two floating-point numbers
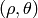 , where
, where 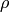 is a distance between (0,0) point and the line, and
is a distance between (0,0) point and the line, and 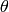 is the angle between x-axis and the normal to the line. Thus, the matrix must be (the created sequence will be) of CV_32FC2 type
is the angle between x-axis and the normal to the line. Thus, the matrix must be (the created sequence will be) of CV_32FC2 type - CV_HOUGH_PROBABILISTIC probabilistic Hough transform (more efficient in case if picture contains a few long linear segments). It returns line segments rather than the whole line. Each segment is represented by starting and ending points, and the matrix must be (the created sequence will be) of CV_32SC4 type
- CV_HOUGH_MULTI_SCALE multi-scale variant of the classical Hough transform. The lines are encoded the same way as CV_HOUGH_STANDARD
- CV_HOUGH_STANDARD classical or standard Hough transform. Every line is represented by two floating-point numbers
- rho – Distance resolution in pixel-related units
- theta – Angle resolution measured in radians
- threshold – Threshold parameter. A line is returned by the function if the corresponding accumulator value is greater than threshold
- param1 –
The first method-dependent parameter:
- For the classical Hough transform it is not used (0).
- For the probabilistic Hough transform it is the minimum line length.
- For the multi-scale Hough transform it is the divisor for the distance resolution . (The coarse distance resolution will be and the accurate resolution will be
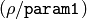 ).
).
- param2 –
The second method-dependent parameter:
- For the classical Hough transform it is not used (0).
- For the probabilistic Hough transform it is the maximum gap between line segments lying on the same line to treat them as a single line segment (i.e. to join them).
- For the multi-scale Hough transform it is the divisor for the angle resolution . (The coarse angle resolution will be and the accurate resolution will be
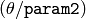 ).
).
The function implements a few variants of the Hough transform for line detection.
Example. Detecting lines with Hough transform.
/* This is a standalone program. Pass an image name as a first parameter
of the program. Switch between standard and probabilistic Hough transform
by changing "#if 1" to "#if 0" and back */
#include <cv.h>
#include <highgui.h>
#include <math.h>
int main(int argc, char** argv)
{
IplImage* src;
if( argc == 2 && (src=cvLoadImage(argv[1], 0))!= 0)
{
IplImage* dst = cvCreateImage( cvGetSize(src), 8, 1 );
IplImage* color_dst = cvCreateImage( cvGetSize(src), 8, 3 );
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* lines = 0;
int i;
cvCanny( src, dst, 50, 200, 3 );
cvCvtColor( dst, color_dst, CV_GRAY2BGR );
#if 1
lines = cvHoughLines2( dst,
storage,
CV_HOUGH_STANDARD,
1,
CV_PI/180,
100,
0,
0 );
for( i = 0; i < MIN(lines->total,100); i++ )
{
float* line = (float*)cvGetSeqElem(lines,i);
float rho = line[0];
float theta = line[1];
CvPoint pt1, pt2;
double a = cos(theta), b = sin(theta);
double x0 = a*rho, y0 = b*rho;
pt1.x = cvRound(x0 + 1000*(-b));
pt1.y = cvRound(y0 + 1000*(a));
pt2.x = cvRound(x0 - 1000*(-b));
pt2.y = cvRound(y0 - 1000*(a));
cvLine( color_dst, pt1, pt2, CV_RGB(255,0,0), 3, 8 );
}
#else
lines = cvHoughLines2( dst,
storage,
CV_HOUGH_PROBABILISTIC,
1,
CV_PI/180,
80,
30,
10 );
for( i = 0; i < lines->total; i++ )
{
CvPoint* line = (CvPoint*)cvGetSeqElem(lines,i);
cvLine( color_dst, line[0], line[1], CV_RGB(255,0,0), 3, 8 );
}
#endif
cvNamedWindow( "Source", 1 );
cvShowImage( "Source", src );
cvNamedWindow( "Hough", 1 );
cvShowImage( "Hough", color_dst );
cvWaitKey(0);
}
}
This is the sample picture the function parameters have been tuned for:

And this is the output of the above program in the case of probabilistic Hough transform ( #if 0 case):

PreCornerDetect¶
- void cvPreCornerDetect(const CvArr* image, CvArr* corners, int apertureSize=3)¶
Calculates the feature map for corner detection.
Parameters: - image – Input image
- corners – Image to store the corner candidates
- apertureSize – Aperture parameter for the Sobel operator (see Sobel )
The function calculates the function
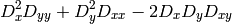
where
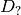 denotes one of the first image derivatives and
denotes one of the first image derivatives and
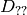 denotes a second image derivative.
denotes a second image derivative.
The corners can be found as local maximums of the function below:
// assume that the image is floating-point
IplImage* corners = cvCloneImage(image);
IplImage* dilated_corners = cvCloneImage(image);
IplImage* corner_mask = cvCreateImage( cvGetSize(image), 8, 1 );
cvPreCornerDetect( image, corners, 3 );
cvDilate( corners, dilated_corners, 0, 1 );
cvSubS( corners, dilated_corners, corners );
cvCmpS( corners, 0, corner_mask, CV_CMP_GE );
cvReleaseImage( &corners );
cvReleaseImage( &dilated_corners );
SampleLine¶
- int cvSampleLine(const CvArr* image CvPoint pt1 CvPoint pt2 void* buffer int connectivity=8)¶
Reads the raster line to the buffer.
Parameters: - image – Image to sample the line from
- pt1 – Starting line point
- pt2 – Ending line point
- buffer – Buffer to store the line points; must have enough size to store
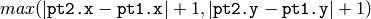 points in the case of an 8-connected line and
points in the case of an 8-connected line and 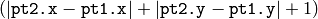 in the case of a 4-connected line
in the case of a 4-connected line - connectivity – The line connectivity, 4 or 8
The function implements a particular application of line iterators. The function reads all of the image points lying on the line between pt1 and pt2 , including the end points, and stores them into the buffer.
Help and Feedback
You did not find what you were looking for?- Try the FAQ.
- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.