K Nearest Neighbors¶
The algorithm caches all of the training samples, and predicts the response for a new sample by analyzing a certain number ( K ) of the nearest neighbors of the sample (using voting, calculating weighted sum etc.) The method is sometimes referred to as “learning by example”, because for prediction it looks for the feature vector with a known response that is closest to the given vector.
CvKNearest¶
- CvKNearest¶
K Nearest Neighbors model.
class CvKNearest : public CvStatModel
{
public:
CvKNearest();
virtual ~CvKNearest();
CvKNearest( const CvMat* _train_data, const CvMat* _responses,
const CvMat* _sample_idx=0, bool _is_regression=false, int max_k=32 );
virtual bool train( const CvMat* _train_data, const CvMat* _responses,
const CvMat* _sample_idx=0, bool is_regression=false,
int _max_k=32, bool _update_base=false );
virtual float find_nearest( const CvMat* _samples, int k, CvMat* results,
const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0 ) const;
virtual void clear();
int get_max_k() const;
int get_var_count() const;
int get_sample_count() const;
bool is_regression() const;
protected:
...
};
CvKNearest::train¶
- bool CvKNearest::train(const CvMat* _train_data, const CvMat* _responses, const CvMat* _sample_idx=0, bool is_regression=false, int _max_k=32, bool _update_base=false)¶
- Trains the model.
The method trains the K-Nearest model. It follows the conventions of generic train “method” with the following limitations: only CV _ ROW _ SAMPLE data layout is supported, the input variables are all ordered, the output variables can be either categorical ( is_regression=false ) or ordered ( is_regression=true ), variable subsets ( var_idx ) and missing measurements are not supported.
The parameter _max_k specifies the number of maximum neighbors that may be passed to the method find_nearest .
The parameter _update_base specifies whether the model is trained from scratch ( _update_base=false ), or it is updated using the new training data ( _update_base=true ). In the latter case the parameter _max_k must not be larger than the original value.
CvKNearest::find_nearest¶
- float CvKNearest::find_nearest(const CvMat* _samples, int k, CvMat* results=0, const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0) const¶
- Finds the neighbors for the input vectors.
For each input vector (which are the rows of the matrix
_samples
) the method finds the
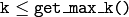 nearest neighbor. In the case of regression,
the predicted result will be a mean value of the particular vector’s
neighbor responses. In the case of classification the class is determined
by voting.
nearest neighbor. In the case of regression,
the predicted result will be a mean value of the particular vector’s
neighbor responses. In the case of classification the class is determined
by voting.
For custom classification/regression prediction, the method can optionally return pointers to the neighbor vectors themselves ( neighbors , an array of k*_samples->rows pointers), their corresponding output values ( neighbor_responses , a vector of k*_samples->rows elements) and the distances from the input vectors to the neighbors ( dist , also a vector of k*_samples->rows elements).
For each input vector the neighbors are sorted by their distances to the vector.
If only a single input vector is passed, all output matrices are optional and the predicted value is returned by the method.
#include "ml.h"
#include "highgui.h"
int main( int argc, char** argv )
{
const int K = 10;
int i, j, k, accuracy;
float response;
int train_sample_count = 100;
CvRNG rng_state = cvRNG(-1);
CvMat* trainData = cvCreateMat( train_sample_count, 2, CV_32FC1 );
CvMat* trainClasses = cvCreateMat( train_sample_count, 1, CV_32FC1 );
IplImage* img = cvCreateImage( cvSize( 500, 500 ), 8, 3 );
float _sample[2];
CvMat sample = cvMat( 1, 2, CV_32FC1, _sample );
cvZero( img );
CvMat trainData1, trainData2, trainClasses1, trainClasses2;
// form the training samples
cvGetRows( trainData, &trainData1, 0, train_sample_count/2 );
cvRandArr( &rng_state, &trainData1, CV_RAND_NORMAL, cvScalar(200,200), cvScalar(50,50) );
cvGetRows( trainData, &trainData2, train_sample_count/2, train_sample_count );
cvRandArr( &rng_state, &trainData2, CV_RAND_NORMAL, cvScalar(300,300), cvScalar(50,50) );
cvGetRows( trainClasses, &trainClasses1, 0, train_sample_count/2 );
cvSet( &trainClasses1, cvScalar(1) );
cvGetRows( trainClasses, &trainClasses2, train_sample_count/2, train_sample_count );
cvSet( &trainClasses2, cvScalar(2) );
// learn classifier
CvKNearest knn( trainData, trainClasses, 0, false, K );
CvMat* nearests = cvCreateMat( 1, K, CV_32FC1);
for( i = 0; i < img->height; i++ )
{
for( j = 0; j < img->width; j++ )
{
sample.data.fl[0] = (float)j;
sample.data.fl[1] = (float)i;
// estimates the response and get the neighbors' labels
response = knn.find_nearest(&sample,K,0,0,nearests,0);
// compute the number of neighbors representing the majority
for( k = 0, accuracy = 0; k < K; k++ )
{
if( nearests->data.fl[k] == response)
accuracy++;
}
// highlight the pixel depending on the accuracy (or confidence)
cvSet2D( img, i, j, response == 1 ?
(accuracy > 5 ? CV_RGB(180,0,0) : CV_RGB(180,120,0)) :
(accuracy > 5 ? CV_RGB(0,180,0) : CV_RGB(120,120,0)) );
}
}
// display the original training samples
for( i = 0; i < train_sample_count/2; i++ )
{
CvPoint pt;
pt.x = cvRound(trainData1.data.fl[i*2]);
pt.y = cvRound(trainData1.data.fl[i*2+1]);
cvCircle( img, pt, 2, CV_RGB(255,0,0), CV_FILLED );
pt.x = cvRound(trainData2.data.fl[i*2]);
pt.y = cvRound(trainData2.data.fl[i*2+1]);
cvCircle( img, pt, 2, CV_RGB(0,255,0), CV_FILLED );
}
cvNamedWindow( "classifier result", 1 );
cvShowImage( "classifier result", img );
cvWaitKey(0);
cvReleaseMat( &trainClasses );
cvReleaseMat( &trainData );
return 0;
}
Help and Feedback
You did not find what you were looking for?- Try the FAQ.
- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.