Clustering and Search in Multi-Dimensional Spaces¶
KMeans2¶
- KMeans2(samples, nclusters, labels, termcrit) → None¶
Splits set of vectors by a given number of clusters.
Parameters: - samples (CvArr) – Floating-point matrix of input samples, one row per sample
- nclusters (int) – Number of clusters to split the set by
- labels (CvArr) – Output integer vector storing cluster indices for every sample
- termcrit (CvTermCriteria) – Specifies maximum number of iterations and/or accuracy (distance the centers can move by between subsequent iterations)
The function
cvKMeans2
implements a k-means algorithm that finds the
centers of
nclusters
clusters and groups the input samples
around the clusters. On output,
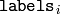 contains a cluster index for
samples stored in the i-th row of the
samples
matrix.
contains a cluster index for
samples stored in the i-th row of the
samples
matrix.
Help and Feedback
You did not find what you were looking for?- Try the FAQ.
- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.