Clustering¶
cv::kmeans¶
- double kmeans(const Mat& samples, int clusterCount, Mat& labels, TermCriteria termcrit, int attempts, int flags, Mat* centers)¶
Finds the centers of clusters and groups the input samples around the clusters.
Parameters: - samples – Floating-point matrix of input samples, one row per sample
- clusterCount – The number of clusters to split the set by
- labels – The input/output integer array that will store the cluster indices for every sample
- termcrit – Specifies maximum number of iterations and/or accuracy (distance the centers can move by between subsequent iterations)
- attempts – How many times the algorithm is executed using different initial labelings. The algorithm returns the labels that yield the best compactness (see the last function parameter)
- flags –
It can take the following values:
- KMEANS_RANDOM_CENTERS Random initial centers are selected in each attempt
- KMEANS_PP_CENTERS Use kmeans++ center initialization by Arthur and Vassilvitskii
- KMEANS_USE_INITIAL_LABELS During the first (and possibly the only) attempt, the
- function uses the user-supplied labels instaed of computing them from the initial centers. For the second and further attempts, the function will use the random or semi-random centers (use one of KMEANS_*_CENTERS flag to specify the exact method)
- centers – The output matrix of the cluster centers, one row per each cluster center
The function
kmeans
implements a k-means algorithm that finds the
centers of
clusterCount
clusters and groups the input samples
around the clusters. On output,
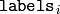 contains a 0-based cluster index for
the sample stored in the
contains a 0-based cluster index for
the sample stored in the
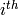 row of the
samples
matrix.
row of the
samples
matrix.
The function returns the compactness measure, which is computed as
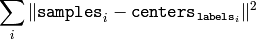
after every attempt; the best (minimum) value is chosen and the corresponding labels and the compactness value are returned by the function. Basically, the user can use only the core of the function, set the number of attempts to 1, initialize labels each time using some custom algorithm and pass them with ( flags = KMEANS_USE_INITIAL_LABELS ) flag, and then choose the best (most-compact) clustering.
cv::partition¶
- template<typename _Tp, class _EqPredicate> int()¶
- partition(const vector<_Tp>& vec, vector<int>& labels, _EqPredicate predicate=_EqPredicate())¶
Splits an element set into equivalency classes.
Parameters: - vec – The set of elements stored as a vector
- labels – The output vector of labels; will contain as many elements as vec . Each label labels[i] is 0-based cluster index of vec[i]
- predicate – The equivalence predicate (i.e. pointer to a boolean function of two arguments or an instance of the class that has the method bool operator()(const _Tp& a, const _Tp& b) . The predicate returns true when the elements are certainly if the same class, and false if they may or may not be in the same class
The generic function
partition
implements an
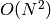 algorithm for
splitting a set of
algorithm for
splitting a set of
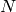 elements into one or more equivalency classes, as described in
http://en.wikipedia.org/wiki/Disjoint-set_data_structure
. The function
returns the number of equivalency classes.
elements into one or more equivalency classes, as described in
http://en.wikipedia.org/wiki/Disjoint-set_data_structure
. The function
returns the number of equivalency classes.
Help and Feedback
You did not find what you were looking for?- Try the Cheatsheet.
- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.