動的構造体¶
CvMemStorage¶
- CvMemStorage¶
動的に拡張可能なメモリストレージ.
typedef struct CvMemStorage
{
struct CvMemBlock* bottom;/* 最初に確保されたブロック */
struct CvMemBlock* top; /* 現在のメモリブロック − スタックの先頭 */
struct CvMemStorage* parent; /* 新たなブロックを確保する場所 */
int block_size; /* ブロックサイズ */
int free_space; /* top ブロック内の利用可能領域サイズ(バイト単位) */
} CvMemStorage;
メモリストレージは,シーケンスデータや輪郭データ,細分化データなどの動的に拡張されるデータ構造体を格納するための低レベル構造体です.これは,同一サイズのメモリブロックのリストとして構成されています. bottom フィールドはブロックのリストの先頭を表します. top フィールドは現在使われているメモリブロックを表しますが,これはリストの最後のブロックとは限りません. bottom と top の間にある全てのブロック( top 自身は含みません)は,完全に占有済みであると見なされます.また, top と最終ブロックの間にある全てのブロック( top 自身は含みません)は,利用可能領域と見なされます.そして, top 自身は部分的に占有されていると見なされ, top 内に残された利用可能領域サイズ(バイト単位)は, free_space で表されます.
新しいメモリ領域は,関数 MemStorageAlloc によって直接的に確保されるか, SeqPush や GraphAddEdge などの高レベル関数によって間接的に確保されます.このメモリ領域は, current ブロックの最後部分に収まる場合には, 常に そこに確保されます.新しいメモリを確保した後は,確保された領域のサイズ+適切なアラインメントを保つためのパディングサイズ分が, free_space から差し引かれます.確保される領域が top 内の利用可能領域に収まらない場合は,リストの次のストレージブロックが top として用いられ, free_space はメモリ確保より前にブロックサイズにリセットされます.
リスト内に利用可能ブロックが存在しない場合,新しいブロックが確保され(あるいは,親メモリストレージから借りて,これについては CreateChildMemStorage を参照してください),リストの最後に追加されます.このように,ストレージはスタックとして振る舞い, bottom がスタックの底を,( top , free_space )のペアがスタックの先頭を表します.スタックの先頭は, SaveMemStoragePos で保存, RestoreMemStoragePos で復元され, ClearMemStorage によってリセットされます.
CvMemBlock¶
- CvMemBlock¶
メモリストレージブロック.
typedef struct CvMemBlock
{
struct CvMemBlock* prev;
struct CvMemBlock* next;
} CvMemBlock;
構造体
CvMemBlock
は,メモリストレージ内の1つのブロックを表します.メモリブロック内で,実際のデータはヘッダ領域の後ろに書き込まれます.つまり,メモリブロック内の
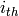 バイトは,
((char*)(mem_block_ptr+1))[i]
という式で取り出すことができます.しかし通常,ストレージ構造体のフィールドに直接アクセスする必要はありません.
バイトは,
((char*)(mem_block_ptr+1))[i]
という式で取り出すことができます.しかし通常,ストレージ構造体のフィールドに直接アクセスする必要はありません.
CvMemStoragePos¶
- CvMemStoragePos¶
メモリストレージの位置.
typedef struct CvMemStoragePos
{
CvMemBlock* top;
int free_space;
} CvMemStoragePos;
この構造体は, SaveMemStoragePos によって保存され RestoreMemStoragePos によって復元される,スタックの先頭の位置を格納しています.
CvSeq¶
- CvSeq¶
動的に拡張可能なシーケンス.
#define CV_SEQUENCE_FIELDS() \
int flags; /* 様々なフラグ */ \
int header_size; /* シーケンスのヘッダサイズ */ \
struct CvSeq* h_prev; /* 1つ前のシーケンスへのポインタ */ \
struct CvSeq* h_next; /* 1つ後のシーケンスへのポインタ */ \
struct CvSeq* v_prev; /* (2番目の)1つ前のシーケンスへのポインタ */ \
struct CvSeq* v_next; /* (2番目の)1つ後のシーケンスへのポインタ */ \
int total; /* 要素の総数 */ \
int elem_size;/* シーケンス要素のサイズ */ \
char* block_max;/* 最後のブロックの最大値境界 */ \
char* ptr; /* 現在の書き込みポインタ */ \
int delta_elems; /* シーケンス拡張の際に確保する要素数(シーケンスの粒度) */ \
CvMemStorage* storage; /* シーケンスが確保される場所 */ \
CvSeqBlock* free_blocks; /* 利用可能ブロックのリスト */ \
CvSeqBlock* first; /* 先頭のシーケンスブロックへのポインタ */
typedef struct CvSeq
{
CV_SEQUENCE_FIELDS()
} CvSeq;
構造体 CvSeq は,OpenCV の全ての動的データ構造体の基本型になっています.
上記の補助マクロによる特殊な定義方法を用いることで,簡単に構造体 CvSeq にメンバを追加して拡張できます. CvSeq を拡張するためには,ユーザが新しい構造体を定義し,マクロ CV_SEQUENCE_FIELDS() によって列挙される CvSeq フィールドの最後尾にユーザ定義のフィールドを追加します.
シーケンスには,密なシーケンスと疎なシーケンスの2種類が存在します.密なシーケンスの基本型は, CvSeq です.これは,ベクトル,スタック,キュー,デックなどの動的に拡張可能な 1 次元配列を表現するために用いられます.これらは,データ内部に空白部を持たないので,シーケンスの端ではない場所の要素が削除される場合,あるいはそこに要素が追加される場合,その場所から近い方の終端までの要素が全てシフトされます.疎なシーケンスの基本型は, CvSet ですが,その詳細は後述します.このシーケンスはノードのシーケンスであり,各ノードは,ノードフラグなどを用いて「データにより占有済み」か「空きがあり利用可能」を示されています.この様なシーケンスは,セット,グラフ,ハッシュテーブルなどの順番のないデータ構造を表現するために用いられます.
フィールド header_size は,シーケンスヘッダの実際のサイズを示しており,これは sizeof(CvSeq) 以上の値となります.
フィールド h_prev , h_next , v_prev , v_next は,複数のシーケンスを用いて階層構造を作成するために利用できます.フィールド h_prev と h_next は,同一階層の前後のシーケンスを指すのに対し,フィールド v_prev と v_next は,上下方向における前後のシーケンス,つまり自分の親と最初の子を指します.しかし,これらの上下や左右は単なる名前にすぎず,これらのポインタを別の目的で利用することもできます.
フィールド first は,最初のシーケンスブロックを指します.この構造については後述します.
フィールド total は,密なシーケンスでは実際の要素の個数,疎なシーケンスでは領域確保されたノードの個数,を表します.
フィールド flags では,上位 16 ビットに特定の動的型シグネチャ(密なシーケンスでは CV_SEQ_MAGIC_VAL ,疎なシーケンスでは CV_SET_MAGIC_VAL )情報が入り,それに続きシーケンスに関するその他の情報が格納されています.また,最下位 CV_SEQ_ELTYPE_BITS ビットには,要素の型の IDが入っています.しかし,シーケンスを扱う関数のほとんどは,この要素の型ではなく, elem_size で示される要素サイズを利用します.シーケンスが CvMat 型で表すような数値データを持つ場合,そのシーケンスの要素の型は,対応する CvMat の要素の型と一致します.例えば,2次元座標のシーケンスでは CV_32SC2 が,浮動小数点数のシーケンスでは CV_32FC1 が用いられます.マクロ CV_SEQ_ELTYPE(seq_header_ptr) は,シーケンス要素の型を返します.数値シーケンスを扱う関数は, elem_size が型サイズから計算された値と一致するかどうかをチェックします. CvMat と互換性がある型以外にも, cvtypes.h で要素型が定義されています:
標準的なシーケンス要素
#define CV_SEQ_ELTYPE_POINT CV_32SC2 /* (x,y) */
#define CV_SEQ_ELTYPE_CODE CV_8UC1 /* フリーマンコード: 0..7 */
#define CV_SEQ_ELTYPE_GENERIC 0 /* 一般的なシーケンス要素型 */
#define CV_SEQ_ELTYPE_PTR CV_USRTYPE1 /* =6 */
#define CV_SEQ_ELTYPE_PPOINT CV_SEQ_ELTYPE_PTR /* &elem:他のシーケンスの要素へのポインタ */
#define CV_SEQ_ELTYPE_INDEX CV_32SC1 /* #elem:他のシーケンスの要素のインデックス */
#define CV_SEQ_ELTYPE_GRAPH_EDGE CV_SEQ_ELTYPE_GENERIC /* &next_o,
&next_d, &vtx_o, &vtx_d */
#define CV_SEQ_ELTYPE_GRAPH_VERTEX CV_SEQ_ELTYPE_GENERIC /* 最初の辺, &(x,y) */
#define CV_SEQ_ELTYPE_TRIAN_ATR CV_SEQ_ELTYPE_GENERIC /* 二分木の頂点ノード */
#define CV_SEQ_ELTYPE_CONNECTED_COMP CV_SEQ_ELTYPE_GENERIC /* 連結成分 */
#define CV_SEQ_ELTYPE_POINT3D CV_32FC3 /* (x,y,z) */
これに続く CV_SEQ_KIND_BITS ビットでは,シーケンスの種類を指定します:
標準的なシーケンスの種類
/* 一般的な(指定がない場合の)シーケンスの種類 */
#define CV_SEQ_KIND_GENERIC (0 << CV_SEQ_ELTYPE_BITS)
/* 密なシーケンスの小分類 */
#define CV_SEQ_KIND_CURVE (1 << CV_SEQ_ELTYPE_BITS)
#define CV_SEQ_KIND_BIN_TREE (2 << CV_SEQ_ELTYPE_BITS)
/* 疎なシーケンス(またはセット)の小分類 */
#define CV_SEQ_KIND_GRAPH (3 << CV_SEQ_ELTYPE_BITS)
#define CV_SEQ_KIND_SUBDIV2D (4 << CV_SEQ_ELTYPE_BITS)
残りのビットは,これ以外のシーケンスや要素を識別するために用いられます.例えば,多くの点で構成される曲線 (CV_SEQ_KIND_CURVE|CV_SEQ_ELTYPE_POINT) は, CV_SEQ_FLAG_CLOSED フラグがあれば CV_SEQ_POLYGON に属するし,さらに別のフラグが利用されていれば,それの小分類に属します.多くの輪郭処理関数は,入力シーケンスの種類をチェックし,サポートしていない種類であればエラーになります.また,ファイル cvtypes.h には,全ての定義済みシーケンスやシーケンスの種類を取得する補助マクロが記述されています.シーケンスブロックの定義を以下に示します.
CvSeqBlock¶
- CvSeqBlock¶
連続シーケンスブロック.
typedef struct CvSeqBlock
{
struct CvSeqBlock* prev; /* 前のシーケンスブロック */
struct CvSeqBlock* next; /* 後のシーケンスブロック */
int start_index; /* ブロックの先頭要素のインデックス +
sequence->first->start_index */
int count; /* ブロック内の要素数 */
char* data; /* ブロックの先頭要素へのポインタ */
} CvSeqBlock;
シーケンスブロックは,循環双方向リストを構成しているので,ポインタ prev と next は同じシーケンス内にある前後のシーケンスブロックを指し,値が NULL になることはありません.つまり,最後のブロックの next は最初のブロックを指し,最初のブロックの prev は最後のブロックを指しています.フィールド start_index と count を利用すると,シーケンス内でのブロックの位置を求めることができます.例えば,シーケンスが10個の要素を持ち,3個,5個,2個の要素を持つ3つのブロックに分かれていて,最初のブロックのパラメータが start_index = 2 である場合を考えます.この場合,それぞれのシーケンスブロックの (start_index, count) の値は,(2,3),(5, 5),(10, 2) となります.最初のブロックの start_index は,シーケンスの先頭に別の要素が挿入された場合を除いて,通常は 0 です.
CvSlice¶
- CvSlice¶
シーケンスのスライス.
typedef struct CvSlice
{
int start_index;
int end_index;
} CvSlice;
inline CvSlice cvSlice( int start, int end );
#define CV_WHOLE_SEQ_END_INDEX 0x3fffffff
#define CV_WHOLE_SEQ cvSlice(0, CV_WHOLE_SEQ_END_INDEX)
/* シーケンスのスライス長を求めます. */
int cvSliceLength( CvSlice slice, const CvSeq* seq );
シーケンスを扱う関数のいくつかは, CvSlice slice パラメータを引数にとります.これは,デフォルトではシーケンズ全体を表す (CV _ WHOLE _ SEQ) であることが多いです. start_index や end_index に,負の値やシーケンス長を越える値が与えられるかもしれませんが,その場合でも, start_index はスライス範囲に含まれ, end_index は含まれません.これらの値が等しい場合,スライスは空であると見なされます(つまり,スライス内に含まれる要素がない状態).シーケンスは,循環構造として扱われるので,シーケンスの最後付近の要素とシーケンスの最初付近の要素を1つのスライスで選択することもできます.例えば,10個の要素を持つシーケンスにおいて,スライス cvSlice(-2, 3) は,最後の1つ手前(8番),最後(9番),最初(0番),2つ目(1番)そして3つ目(2番)の5個の要素を含みます.このような引数の正規化を行うために,この関数はまず,スライス長を決定する関数 SliceLength を呼び出します.そして,スライスの start_index が GetSeqElem の引数と同様に正規化されます(つまり,負のインデックスが使えるようになります).実際のスライスは,正規化された start_index から始まり,そこから SliceLength 個の要素分だけの長さを持ちます(これも,シーケンスが循環構造であることを仮定している点に注意してください).
もし,スライス引数をとらない関数でシーケンスの一部分だけを処理したい場合は,関数 SeqSlice を使って部分シーケンスを選択したり,関数 CvtSeqToArray で連続バッファにコピーしたり(この場合は,続けて MakeSeqHeaderForArray を用いることが多い)する方法があります.
CvSet¶
- CvSet¶
ノードの集合.
typedef struct CvSetElem
{
int flags; /* これが空きノードなら負,そうでなければ 0 以上の値 */
struct CvSetElem* next_free; /* これが空きノードの場合,次の空きノードへのポインタ */
}
CvSetElem;
#define CV_SET_FIELDS() \
CV_SEQUENCE_FIELDS() /* CvSeq から引き継ぐ */ \
struct CvSetElem* free_elems; /* 空きノードのリスト */
typedef struct CvSet
{
CV_SET_FIELDS()
} CvSet;
構造体 CvSet は,OpenCV における疎なデータ構造の基本型です.
上記の宣言のとおり, CvSet は CvSeq を基にしており,それに空きノードのリストを表すフィールド free_elems を加えたものです.つまり,セットのノードは,空きノードであろうとなかろうと,内部的にはシーケンスの要素になります.密なシーケンスの要素に対しては特に制限はありませんが,セット(と,それから派生する構造体)の要素は必ず整数型のフィールドで始まり, CvSetElem 構造体に一致する必要があります.何故なら,これら2つのフィールド(整数型と空きノードへのポインタ)は,空きノードのリストを持つセットを構成するために不可欠なものだからです.もし,あるノードが空きノードならば,そのフィールド flags は負の値を持ち(つまり,フィールドの最上位ビット:MSB がセットされている状態),フィールド next_free は,次の空きノードを指す(最初の空きノードは, CvSet のフィールド free_elems によって参照されます).また,ノードが使用されている場合,フィールド flags は正の値であり, ( set_elem->flags & CV_SET_ELEM_IDX_MASK ) の式を用いて抽出されるノードのインデックスを含みます.ノードの残りの領域は,ユーザによって決定されます.特に,使用ノードは空きノードのようにリンクされないので,2番目のフィールドをこのようなリンクやその他の目的のために使うことができます.マクロ CV_IS_SET_ELEM(set_elem_ptr) を用いると,指定したノードが空いているか使用されているかを判断することが可能です.
初期状態では,セットとそのリストは空です.そのセットに対して新しいノードが要求されると,空きノードリストからノードが1つ取り出され,空きノードリストが更新されます.空きノードリストが空になると,新しいシーケンスブロックが確保され,そのブロック内の全ノードが空きノードリストに追加されます.したがって,セットのフィールド total は,使用ノードと空きノードの両方を含む全ノードの個数となります.使用ノードが解放されると,それは空きノードリストに加えられます.また,最後に解放されるノードは,最初に使用されたノードでもあります.
OpenCV では, CvSet が,グラフ( CvGraph )や,疎な多次元配列( CvSparseMat ),平面細分割( CvSubdiv2D )などを表現するために用いられます.
CvGraph¶
- CvGraph¶
重み付きの有向または無向グラフ.
#define CV_GRAPH_VERTEX_FIELDS() \
int flags; /* 頂点フラグ */ \
struct CvGraphEdge* first; /* 最初の接続辺 */
typedef struct CvGraphVtx
{
CV_GRAPH_VERTEX_FIELDS()
}
CvGraphVtx;
#define CV_GRAPH_EDGE_FIELDS() \
int flags; /* 辺フラグ */ \
float weight; /* 辺の重み */ \
struct CvGraphEdge* next[2]; /* 接続リスト内の次の辺. */ \
/* next[0] が始点,next[1] が終点 */ \
struct CvGraphVtx* vtx[2]; /* vtx[0] が始点,vtx[1] が終点 */
typedef struct CvGraphEdge
{
CV_GRAPH_EDGE_FIELDS()
}
CvGraphEdge;
#define CV_GRAPH_FIELDS() \
CV_SET_FIELDS() /* 頂点のセット */ \
CvSet* edges; /* 辺のセット */
typedef struct CvGraph
{
CV_GRAPH_FIELDS()
}
CvGraph;
構造体 CvGraph は,OpenCV で利用されるグラフの基本型です.
グラフ構造は,共通のプロパティとグラフの頂点を表す CvSet を基にしており,さらにグラフの辺を表す別のセットをメンバに持ちます.
頂点,辺,グラフヘッダ構造体は,OpenCV の他の拡張可能な構造体と同じ方法で,つまり,拡張と構造体のカスタマイズを容易にするマクロを介して,宣言されます.頂点と辺の構造体は,明示的に CvSetElem を基にしているわけではありませんが,セット要素であるための2つの条件,つまり先頭に整数型のフィールドを持ち,CvSetElem 構造体にぴったり収まる事,を満たしています.また,フィールド flags は,頂点や辺が使用されている状態を示すために使われるだけでなく,他の目的,例えばグラフの走査( CreateGraphScanner などを参照してください)にも利用されるので,これらのフィールドを直接利用することは避けるべきです.
グラフは辺のセットとして表現され,各辺はそこに接続する辺のリストを持ちます.情報の重複をできるだけ避けるために,異なる頂点への接続リストが交互に配置されます.
グラフは,有向または無向,のいずれかです.無向グラフの場合,頂点
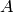 から
から
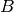 への接続と
から
への接続の区別はなく,ある瞬間にグラフ上に存在できるのは片方だけです.これらの接続はそれぞれ,辺
への接続と
から
への接続の区別はなく,ある瞬間にグラフ上に存在できるのは片方だけです.これらの接続はそれぞれ,辺
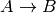 と辺
と辺
 の両方を表します.
の両方を表します.
CvGraphScanner¶
- CvGraphScanner¶
グラフ走査状態を表す構造体.
typedef struct CvGraphScanner
{
CvGraphVtx* vtx; /* 現在の頂点(あるいは,現在の辺の始点) */
CvGraphVtx* dst; /* 現在の辺の終点 */
CvGraphEdge* edge; /* 現在の辺 */
CvGraph* graph; /* グラフ */
CvSeq* stack; /* グラフの頂点のスタック */
int index; /* 走査済み頂点の下限 */
int mask; /* イベントマスク */
}
CvGraphScanner;
構造体 CvGraphScanner は,深さ優先走査で利用されます.以下の関数の説明を参照してください.
cvmacro 木のノードの種類を宣言するための補助マクロ.
マクロ CV_TREE_NODE_FIELDS() は,階層構造(木)を構成することができる構造体を宣言するために利用されます.例えば,すべての動的構造体の基本型である CvSeq もその1つです.このマクロを利用して宣言されたノードで構成された木構造は,このセクションで後述する各関数を用いて処理することができます.
CvTreeNodeIterator¶
- CvTreeNodeIterator¶
木のノードのためのイテレータ構造体.
typedef struct CvTreeNodeIterator
{
const void* node;
int level;
int max_level;
}
CvTreeNodeIterator;
#define CV_TREE_NODE_FIELDS(node_type) \
int flags; /* 様々なフラグ */ \
int header_size; /* シーケンスヘッダのサイズ */ \
struct node_type* h_prev; /* 1 つ前のシーケンスへのポインタ */ \
struct node_type* h_next; /* 1 つ後のシーケンスへのポインタ */ \
struct node_type* v_prev; /* ( 2 番目の) 1 つ前のシーケンスへのポインタ */ \
struct node_type* v_next; /* ( 2 番目の) 1 つ後のシーケンスへのポインタ */ \
構造体 CvTreeNodeIterator は,木構造内を走査するために用いられます.それぞれの木ノードは, CV_TREE_NODE_FIELDS(...) マクロによって定義されるフィールドで始まるべきです.C++の用語で言えば,木ノードは,次の構造体から「派生した」構造体であるべきです.
struct _BaseTreeNode
{
CV_TREE_NODE_FIELDS(_BaseTreeNode);
}
CvSeq から派生した, CvSeq , CvSet , CvGraph および,その他の動的構造体は,この必要条件を満たします.
cv::ClearGraph¶
この関数は,グラフからすべての頂点と辺を削除します.この計算量は,O(1)です.
cv::ClearMemStorage¶
- void cvClearMemStorage(CvMemStorage* storage)¶
メモリストレージをクリアします.
Parameter: storage – メモリストレージ
この関数は,ストレージの先頭(利用可能領域の先頭)を一番最初の位置に戻します.また,この関数は,メモリを解放することはしません.もし親ストレージが存在すれば,全てのブロックが親に返されます.
cv::ClearSeq¶
この関数は,シーケンスの全要素を削除します.また,この関数は,そのメモリ領域をストレージブロックに返しませんが,後でこのシーケンスに要素を追加する際には,同じメモリ領域が使われます.計算量は O(1) です.
cv::ClearSet¶
この関数は,セットから全ノードを削除します.計算量は,O(1) です.
cv::CloneGraph¶
- CvGraph* cvCloneGraph(const CvGraph* graph, CvMemStorage* storage)¶
グラフのコピーを作成します.
パラメタ: - graph – 複製されるグラフ
- storage – 複製したグラフを格納するストレージ
この関数は,グラフの完全なコピーを作成します.グラフの頂点や辺が外部データへのポインタを持つ場合,そのポインタはコピーしたグラフでも共有されます.この関数は頂点や辺のセットを最適化(デフラグメント)するので,新しいグラフの頂点と接続辺のインデックスが元のグラフと異なる可能性があります.
cv::CloneSeq¶
- CvSeq* cvCloneSeq(const CvSeq* seq, CvMemStorage* storage=NULL)¶
シーケンスのコピーを作成します.
パラメタ: - seq – シーケンス
- storage – 新しいシーケンスヘッダと(もしあれば)コピーされたデータを保存する出力ストレージブロック.これが NULL の場合,入力シーケンスが存在するストレージブロックを使用します
この関数は,入力シーケンスの完全なコピーを作成し,そのポインタを返します.
関数呼び出し
cvCloneSeq( seq, storage )
は,以下と等価です.
cvSeqSlice( seq, CV_WHOLE_SEQ, storage, 1 )
cv::CreateChildMemStorage¶
- CvMemStorage* cvCreateChildMemStorage(CvMemStorage* parent)¶
子メモリストレージを作成します.
Parameter: parent – 親メモリストレージ
この関数は,子メモリストレージを作成します.子メモリストレージは,メモリの確保・解放のメカニズムが異なる以外は,普通のメモリストレージと同じです.子メモリストレージが,ブロックリストに追加するための新しいブロックを必要とする場合,そのブロックを親から借りようとします.親メモリストレージの最初の利用可能ブロックが借り出され,そのブロックは親のブロックリストからは取り除かれます.利用可能なブロックが存在しない場合は,親メモリストレージ自身が新たにメモリを確保するか,親の親メモリストレージが存在すればそこからブロックを借ります.つまり,chain 構造や,各ストレージが別のストレージの子や親になる様なさらに複雑な構造になることが起こり得ます.子メモリストレージが解放されたり,クリアされたりした場合は,すべてのブロックが親に返されます.別の見方をすると,子メモリストレージは単純なメモリストレージと同じであると言えます.
子メモリストレージが,どのような状況で役立つのかを考えてみましょう.与えられたストレージ領域内の動的データを処理して,その結果を同じストレージ領域内に再度書き込む場合を想像してください.一時的に発生するデータを,入出力ストレージと同じ領域内に置くような最も単純な方法の場合,処理後のストレージ領域は,以下のようになります:
子メモリストレージを利用しない動的データ処理
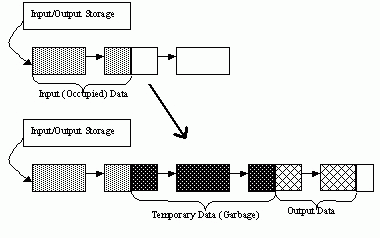
このように,ストレージ内部に「ゴミ」が残っていることが分かります.しかし,処理前に子メモリストレージを作成し,一時的なデータをそこに書き込み,処理後にその子メモリストレージを解放すると,入出力ストレージ内に「ゴミ」が残ることはありません:
子メモリストレージを利用する動的データ処理
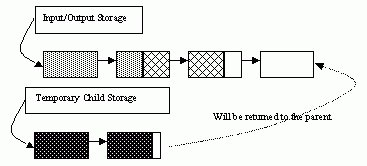
cv::CreateGraph¶
- CvGraph* cvCreateGraph(int graph_flags, int header_size, int vtx_size, int edge_size, CvMemStorage* storage)¶
空のグラフを作成します.
パラメタ: - graph_flags – 作成されるグラフの種類.通常,無向グラフならば CV_SEQ_KIND_GRAPH ,有向グラフならば CV_SEQ_KIND_GRAPH | CV_GRAPH_FLAG_ORIENTED .通常はこのどちらかです
- header_size – グラフのヘッダサイズ, sizeof(CvGraph) 以上の値
- vtx_size – グラフの頂点のサイズ.カスタマイズされた頂点構造体は, CvGraphVtx で始まらなければいけません( CV_GRAPH_VERTEX_FIELDS() を利用)
- edge_size – グラフの辺のサイズ.カスタマイズされた頂点構造体は, CvGraphEdge で始まらなければいけません( CV_GRAPH_EDGE_FIELDS() を利用)
- storage – グラフが格納されるメモリストレージ
この関数は,空のグラフを作成し,そのポインタを返します.
cv::CreateGraphScanner¶
- CvGraphScanner* cvCreateGraphScanner(CvGraph* graph, CvGraphVtx* vtx=NULL, int mask=CV_GRAPH_ALL_ITEMS)¶
グラフの深さ優先走査のための構造体を作成します.
パラメタ: - graph – グラフ
- vtx – 走査開始頂点.これが NULL の場合,先頭の(頂点のシーケンスにおいて最小のインデックスを持つ)頂点から走査が開始されます
- mask –
どのイベントに注目するかを指定するイベントマスク(関数 NextGraphItem は,ユーザにコントロールを戻します).この値は, CV_GRAPH_ALL_ITEMS (全てのイベントに注目)か,あるいは以下のフラグの組み合わせです:
- CV_GRAPH_VERTEX 初めて到達した頂点に来ると,そこで停止します
- CV_GRAPH_TREE_EDGE tree edge で停止します( tree edge は,最後に到達した頂点と次にアクセスされる頂点を接続する辺のことです)
- CV_GRAPH_BACK_EDGE back edge で停止します( back edge は,最後に到達した頂点とその親(たち)を接続する辺のことです)
- CV_GRAPH_FORWARD_EDGE forward edge で停止します( forward edge は,最後に到達した頂点とその子(たち)を接続する辺のことです.これは,有向グラフ走査でのみ利用できます)
- CV_GRAPH_CROSS_EDGE cross edge で停止します( cross edge は,異なる探索木同士,あるいは同じ木の枝同士を接続する辺のことです.これは,有向グラフ走査でのみ利用できます)
- CV_GRAPH_ANY_EDGE すべての辺( tree, back, forward, cross edge )で停止します
- CV_GRAPH_NEW_TREE すべての,新しい探索木の先頭で停止します.走査処理が開始頂点から到達可能なすべての頂点と辺に到達(到達した頂点と辺は木を構成します)しようとする場合,まずグラフ内で到達していない頂点を探し,その頂点から再び走査を行います.そして,新しい木での走査を開始する前に,(初めて cvNextGraphItem が呼ばれた際に探索する,一番最初の木でも) CV_GRAPH_NEW_TREE イベントが発生します.また無向グラフにおいては,それぞれの探索木がグラフの連結成分に相当します
- CV_GRAPH_BACKTRACKING バックトラッキング(探索木の到達済みの頂点に戻ること)の際に,既に到達したすべての頂点で停止します
この関数は,深さ優先走査(深さ優先探索)のための構造体を作成します.初期化された構造体は,関数 NextGraphItem 内での逐次走査に利用されます.
cv::CreateMemStorage¶
- CvMemStorage* cvCreateMemStorage(int blockSize=0)¶
メモリストレージを作成します.
Parameter: blockSize – バイト単位で表されたストレージブロックサイズ.この値が 0 の場合,デフォルト値(現在は,約64K)が利用されます
この関数は,空のメモリストレージオブジェクトを作成します.
cv::CreateSeq¶
- CvSeq* cvCreateSeq(int seqFlags, int headerSize, int elemSize, CvMemStorage* storage)¶
シーケンスを作成します.
パラメタ: - seqFlags – 作成するシーケンスのフラグ.決まった種類のシーケンスだけを処理する関数に渡されるのでなければ,この値を 0 にしても構いません.そうでなければ,定義済みシーケンスのリストから適切な種類を選択する必要があります
- headerSize – シーケンスヘッダのサイズ. sizeof(CvSeq) 以上でなければいけません.また,特定の型やそれを拡張したものが指定される場合,それは基本型ヘッダと矛盾してはいけません
- elemSize – バイト単位で表されるシーケンスの要素サイズ.このサイズはシーケンスの型と矛盾してはいけません.例えば,点群のシーケンスを作成する場合,要素の種類は CV_SEQ_ELTYPE_POINT であり,シーケンスのパラメータ elemSize は sizeof(CvPoint) と等しくなければいけません
- storage – シーケンスの格納場所
この関数は,シーケンスを作成しそのポインタを返します.これは,ストレージブロック内の連続した1つの領域にシーケンスヘッダを確保し,その構造体の4つのフィールド, flags , elemSize , headerSize ,そして storage を,与えられた値で初期化します.また, delta_elems はデフォルト値にセットされ(関数 SetSeqBlockSize で再設定可能です),その他のヘッダフィールドは,最初の sizeof(CvSeq) バイトに続く拡張領域も含め,全てクリアされます.
cv::CreateSet¶
- CvSet* cvCreateSet(int set_flags, int header_size, int elem_size, CvMemStorage* storage)¶
空のセットを作成します.
パラメタ: - set_flags – 作成されるセットの種類
- header_size – セットヘッダのサイズ, sizeof(CvSet) 以上の値です
- elem_size – セット要素のサイズ, CvSetElem 以上の値です
- storage – セットが格納されるストレージ
この関数は,指定されたヘッダサイズと要素サイズを持つ空のセットを作成し,そのポインタを返します.これは, CreateSeq に多少の処理を追加しただけのものです.
cv::CvtSeqToArray¶
- void* cvCvtSeqToArray(const CvSeq* seq, void* elements, CvSlice slice=CV_WHOLE_SEQ)¶
シーケンスを,メモリ上の連続した1つのブロック(配列)にコピーします.
パラメタ: - seq – シーケンス
- elements – 十分なサイズを持った出力配列へのポインタ.これは行列ヘッダではなく,データへのポインタであるべきです
- slice – 配列にコピーされるシーケンスのスライス
この関数は,シーケンス全部あるいはその一部を,指定されたバッファ領域にコピーし,そのバッファへのポインタを返します.
cv::EndWriteSeq¶
この関数は,書き込み処理を終了し,書き込まれたシーケンスへのポインタを返します.また,シーケンスブロックの余り部分をメモリストレージに返すために,最後の不完全なシーケンスブロックを切り詰めます.この処理によって,シーケンスは安全に読み書きできるようになります. cvStartWriteSeq および cvStartAppendToSeq を参照してください.
cv::FindGraphEdge¶
- CvGraphEdge* cvFindGraphEdge(const CvGraph* graph, int start_idx, int end_idx)¶
- グラフ内から(インデックスで指定した)辺を見つけます.
#define cvGraphFindEdge cvFindGraphEdge
param graph: グラフ param start_idx: 辺の始点を示す頂点のインデックス param end_idx: 辺の終点を示す頂点のインデックス.無向グラフの場合は,始点終点の順序は意味がありません
この関数は,指定した2頂点を接続する辺を見つけ,そのポインタを返します.また,辺が存在しない場合は,NULL を返します.
cv::FindGraphEdgeByPtr¶
- CvGraphEdge* cvFindGraphEdgeByPtr(const CvGraph* graph, const CvGraphVtx* startVtx, const CvGraphVtx* endVtx)¶
- グラフ内から(ポインタで指定した)辺を見つけます.
#define cvGraphFindEdgeByPtr cvFindGraphEdgeByPtr
param graph: グラフ param start_idx: 辺の始点を示す頂点へポインタ param end_idx: 辺の終点を示す頂点へのポインタ.無向グラフの場合は,始点終点の順序は意味がありません
この関数は,指定した2頂点を接続する辺を見つけ,そのポインタを返します.また,辺が存在しない場合は,NULL を返します.
cv::FlushSeqWriter¶
- void cvFlushSeqWriter(CvSeqWriter* writer)¶
ライタからシーケンスヘッダを更新する.
Parameter: writer – ライタ構造体
この関数は,書き込み処理中だとしても,(例えば,特定の状態をチェックするといった目的で)要求があればいつでもシーケンス要素を読み出せるようにします.この関数は,シーケンスからの読み出しを可能にするためにシーケンスヘッダを更新します.しかし,ライタはクローズされないので,いつでも書き込み処理を再開する事ができます.フラッシュを頻繁に行うアルゴリズムでは,代わりに SeqPush の利用を考慮した方がよいでしょう.
cv::GetGraphVtx¶
- CvGraphVtx* cvGetGraphVtx(CvGraph* graph, int vtx_idx)¶
インデックスを用いてグラフの頂点を見つけます.
パラメタ: - graph – グラフ
- graph – グラフ
- vtx_idx – 頂点のインデックス
この関数は,インデックスを用いて頂点を検索し,見つかればそのポインタを返します.グラフ内に指定された頂点が存在しなければ NULL を返します.
cv::GetSeqElem¶
#define CV_GET_SEQ_ELEM( TYPE, seq, index ) (TYPE*)cvGetSeqElem( (CvSeq*)(seq), (index) )
param seq: シーケンス param index: 要素を示すインデックス
この関数は,与えられたインデックスが示す要素へのポインタを返します.なお,要素が見つからなかった場合は 0 を返します.この関数は負のインデックスをサポートしており,-1 は最後の要素, -2 は最後から2番目の要素を表します.シーケンスが1つのシーケンスブロックから構成されている可能性が高い場合や,求める要素が最初のブロックにある可能性が高い場合は,代わりにマクロ CV_GET_SEQ_ELEM( elemType, seq, index ) を使うべきです.ここで,パラメータ elemType はシーケンス要素の型(例えば, CvPoint ),パラメータ seq はシーケンス,パラメータ index は求める要素のインデックス,をそれぞれ表します.このマクロはまず,求める要素がシーケンスの最初のブロックにあるかどうかを調べます.そして,あればそのポインタを返し,なければ関数 GetSeqElem を呼び出します.また,インデックスが負の場合は,常に GetSeqElem を呼び出します.要素の総数と比較してブロックの数が十分に少なければ,この計算量は,O(1) となります.
cv::GetSeqReaderPos¶
- int cvGetSeqReaderPos(CvSeqReader* reader)¶
現在のリーダの位置を返します.
Parameter: reader – リーダ構造体
この関数は,(0 ... reader->seq->total - 1 の範囲にある)現在のリーダの位置を返します.
cv::GetSetElem¶
- CvSetElem* cvGetSetElem(const CvSet* setHeader, int index)¶
インデックスで指定されるセットノードを見つけます.
パラメタ: - setHeader – セット
- index – セットノードのインデックス
この関数は,インデックスで指定されるセットノードを見つけ出します.これは,ノードが見つかればそのポインタを返し,インデックスが有効な値ではない場合,あるいは対応するノードが空ノードの場合は 0 を返します.さらに,この関数は GetSeqElem と同様に,ノード位置を表す負のインデックスをサポートします.
cv::GraphAddEdge¶
- int cvGraphAddEdge(CvGraph* graph, int start_idx, int end_idx, const CvGraphEdge* edge=NULL, CvGraphEdge** inserted_edge=NULL)¶
グラフに(インデックスで指定して)辺を追加します.
パラメタ: - graph – グラフ
- start_idx – 辺の始点を示す頂点のインデックス
- end_idx – 辺の終点を示す頂点のインデックス.無向グラフの場合は,始点終点の順序は意味がありません
- edge – オプション.辺を初期化するためのデータ
- inserted_edge – オプション.挿入される辺のアドレスがここに出力されます
この関数は,指定した2頂点を接続します.辺の追加が成功した場合は 1,既に辺が存在する場合は 0,頂点のどちらかが存在しない場合,始点と終点が同じ頂点である場合,その他の致命的な問題がある場合は -1,を返します.この場合(つまり,結果が負の場合)は,デフォルトでエラーを発生させます.
cv::GraphAddEdgeByPtr¶
- int cvGraphAddEdgeByPtr(CvGraph* graph, CvGraphVtx* start_vtx, CvGraphVtx* end_vtx, const CvGraphEdge* edge=NULL, CvGraphEdge** inserted_edge=NULL)¶
グラフに(ポインタで指定して)辺を追加します.
パラメタ: - graph – グラフ
- start_vtx – 辺の始点を示す頂点へのポインタ
- end_vtx – 辺の終点を示す頂点へのポインタ.無向グラフの場合は,始点終点の順序は意味がありません
- edge – オプション.辺を初期化するためのデータ
- inserted_edge – オプション.挿入される辺のアドレスがここに出力されます
この関数は,指定した2頂点を接続します.辺の追加が成功した場合は 1,既に辺が存在する場合は 0,頂点のどちらかが存在しない場合,始点と終点が同じ頂点である場合,その他の致命的な問題がある場合は -1,を返します.この場合(つまり,結果が負の場合)は,デフォルトでエラーを発生させます.
cv::GraphAddVtx¶
- int cvGraphAddVtx(CvGraph* graph, const CvGraphVtx* vtx=NULL, CvGraphVtx** inserted_vtx=NULL)¶
グラフに頂点を追加します.
パラメタ: - graph – グラフ
- vtx – オプション.この引数は,追加される頂点の初期化に利用されます( sizeof(CvGraphVtx) を越えているユーザ定義フィールドだけがコピーされます)
- inserted_vertex – オプション.これが NULL でなければ,新しい頂点のアドレスがここに書き込まれます
この関数は,グラフに頂点を追加し,その頂点のインデックスを返します.
cv::GraphEdgeIdx¶
- int cvGraphEdgeIdx(CvGraph* graph, CvGraphEdge* edge)¶
グラフの辺のインデックスを返します.
パラメタ: - graph – グラフ
- edge – グラフの辺へのポインタ
この関数は,グラフの辺のインデックスを返します.
cv::GraphRemoveEdge¶
- void cvGraphRemoveEdge(CvGraph* graph, int start_idx, int end_idx)¶
グラフから(インデックスで指定して)辺を削除します.
パラメタ: - graph – グラフ
- start_idx – 辺の始点を示す頂点のインデックス
- end_idx – 辺の終点を示す頂点のインデックス.無向グラフの場合は,始点終点の順序は意味がありません
この関数は,指定した2頂点を接続する辺を削除します.指定した頂点が(指定した順序で)接続されていない場合,この関数は何もしません.
cv::GraphRemoveEdgeByPtr¶
- void cvGraphRemoveEdgeByPtr(CvGraph* graph, CvGraphVtx* start_vtx, CvGraphVtx* end_vtx)¶
グラフから(ポインタで指定して)辺を削除します.
パラメタ: - graph – グラフ
- start_idx – 辺の始点を示す頂点へポインタ
- end_idx – 辺の終点を示す頂点へのポインタ.無向グラフの場合は,始点終点の順序は意味がありません
この関数は,指定した2頂点を接続する辺を削除します.指定した頂点が(指定した順序で)接続されていない場合,この関数は何もしません.
cv::GraphRemoveVtx¶
- int cvGraphRemoveVtx(CvGraph* graph, int index)¶
グラフから(インデックスで指定した)頂点を削除します.
パラメタ: - graph – グラフ
- vtx_idx – 削除される頂点のインデックス
この関数は,指定された頂点とその頂点に接続する全ての辺をグラフから削除します.指定された頂点がグラフ内に存在しない場合は,エラーになります.頂点が存在しなかった場合には -1 が,そうでなければ削除された辺の数が返されます.
cv::GraphRemoveVtxByPtr¶
- int cvGraphRemoveVtxByPtr(CvGraph* graph, CvGraphVtx* vtx)¶
グラフから(ポインタで指定した)頂点を削除します.
パラメタ: - graph – グラフ
- vtx – 削除される頂点へのポインタ
この関数は,グラフからポインタで指定された頂点とその頂点に接続する全ての辺を削除します.指定された頂点がグラフ内に存在しない場合は,エラーになります.頂点が存在しなかった場合には -1 が,そうでなければ削除された辺の数が返されます.
cv::GraphVtxDegree¶
- int cvGraphVtxDegree(const CvGraph* graph, int vtxIdx)¶
(インデックスで指定した)頂点に接続している辺の個数を数えます.
パラメタ: - graph – グラフ
- vtx – グラフの頂点のインデックス
この関数は,指定した頂点に接続する(有向グラフの場合,入出両方)辺の個数を返します.辺の数を数えるためには,次のようなコードを利用します:
CvGraphEdge* edge = vertex->first; int count = 0;
while( edge )
{
edge = CV_NEXT_GRAPH_EDGE( edge, vertex );
count++;
}
マクロ CV_NEXT_GRAPH_EDGE( edge, vertex ) は,頂点 vertex に接続する辺の内,辺 edge の次の辺を返します.
cv::GraphVtxDegreeByPtr¶
- int cvGraphVtxDegreeByPtr(const CvGraph* graph, const CvGraphVtx* vtx)¶
(ポインタで指定した)頂点に接続している辺の個数を数えます.
パラメタ: - graph – グラフ
- vtx – グラフの頂点へのポインタ
この関数は,指定した頂点に接続する(有向グラフの場合,入出両方)辺の個数を返します.
cv::GraphVtxIdx¶
- int cvGraphVtxIdx(CvGraph* graph, CvGraphVtx* vtx)¶
グラフの頂点のインデックスを返します.
パラメタ: - graph – グラフ
- vtx – グラフの頂点へのポインタ
この関数は,グラフ内の指定された頂点のインデックスを返します.
cv::InitTreeNodeIterator¶
- void cvInitTreeNodeIterator(CvTreeNodeIterator* tree_iterator, const void* first, int max_level)¶
木ノードのイテレータを初期化します.
パラメタ: - tree_iterator – この関数によって初期化される木ノード用のイテレータ
- first – 走査を開始する最初のノード
- max_level – 木の走査範囲の最大レベル(最初の first ノードを 1レベルとします).例えばこれが 1 の場合, first と同じレベルのノードだけが走査され,2 の場合, first と同レベルのノードに加えて,それらの直接の子ノードも走査されます.それ以上のレベルでも同じようになります
この関数は,木ノードのイテレータを初期化します.これにより,木は深さ優先探索で走査されます.
cv::InsertNodeIntoTree¶
- void cvInsertNodeIntoTree(void* node, void* parent, void* frame)¶
木に新しいノードを加えます.
パラメタ: - node – 挿入されるノード
- parent – 木に既にある親ノード
- frame – トップレベルノード. parent と frame が同じならば,挿入されるノード node のフィールド v_prev は NULL になります.それ以外の場合は parent になります
この関数は,木にノードを追加します.この関数はメモリの確保を行うわけではなく,木ノードのリンクを変更するだけです.
cv::MakeSeqHeaderForArray¶
- CvSeq* cvMakeSeqHeaderForArray(int seq_type, int header_size, int elem_size, void* elements, int total, CvSeq* seq, CvSeqBlock* block)¶
配列に対するシーケンスヘッダを作成します.
パラメタ: - seq_type – 作成されるシーケンスの種類
- header_size – シーケンスのヘッダサイズ.パラメータ seq は,これ以上のサイズを持つ構造体を指さなければいけません
- elem_size – シーケンス要素のサイズ
- elements – シーケンスを構成する要素
- total – シーケンスの要素の総数.配列の要素数は,この値と等しくなければいけません
- seq – シーケンスヘッダとして利用される変数へのポインタ
- block – シーケンスブロックのヘッダとして利用される変数へのポインタ
この関数は,配列に対するシーケンスヘッダを初期化します.シーケンスブロックとシーケンスヘッダは,ユーザによって(スタック上などに)確保されなければいけません.また,この関数では,データのコピーは行われません.結果として得られるシーケンスは,単一のブロックで構成され,そのストレージポインタは NULL です.そのため,その要素を読み出すことは可能ですが,このシーケンスに要素を追加しようとすると,多くの場合はエラーになります.
cv::MemStorageAlloc¶
- void* cvMemStorageAlloc(CvMemStorage* storage, size_t size)¶
メモリストレージブロック内にメモリバッファを確保します.
パラメタ: - storage – メモリストレージ
- size – バッファサイズ
この関数は,メモリストレージブロック内にメモリバッファを確保します.バッファサイズは,ストレージのブロックサイズを越えてはならず,越えてしまうとランタイムエラーが起こります.このバッファのアドレスは,(現時点では) CV_STRUCT_ALIGN=sizeof(double) バイト境界にアラインメントが調整されます.
cv::MemStorageAllocString¶
- CvString cvMemStorageAllocString(CvMemStorage* storage, const char* ptr, int len=-1)¶
- メモリストレージブロック内に文字列を確保します.
typedef struct CvString
{
int len;
char* ptr;
}
CvString;
param storage: メモリストレージ param ptr: 文字列 param len: 文字列の長さ(最後の NULL は数えません).これが負の場合,この関数が長さを計算します
この関数は,メモリストレージ内に文字列のコピーを作成します.これは,ユーザ指定の(または,関数内で計算された)文字列長と,コピーされた文字列へのポインタ,の2つのメンバを持つ構造体を返します.
cv::NextGraphItem¶
- int cvNextGraphItem(CvGraphScanner* scanner)¶
グラフの走査処理を,1ステップあるいは数ステップ進めます.
Parameter: scanner – この関数によって更新されるグラフの走査状態構造体
この関数は,ユーザが着目しイベント(つまり,関数 CreateGraphScanner の mask で指定したイベント)が発生するか,完了するまでグラフ内の走査を行います.前者の場合,上述のパラメータ mask の項で説明されたイベントの内1つを返し,次の呼び出しで走査を再開します.後者の場合, CV_GRAPH_OVER (-1) を返します.発生したイベントが CV_GRAPH_VERTEX , CV_GRAPH_BACKTRACKING , CV_GRAPH_NEW_TREE であれば,現在対象となってる頂点が scanner->vtx に格納されます.また,発生したイベントが辺に関連するものであれば,その辺自身が scanner->edge に,辺の始点が scanner->vtx に,そして,辺の終点が scanner->dst に格納されます.
cv::NextTreeNode¶
- void* cvNextTreeNode(CvTreeNodeIterator* tree_iterator)¶
現在の対象ノードを返し,イテレータを次のノードに進めます.
Parameter: tree_iterator – 木ノード用のイテレータ
この関数は,現在の対象ノードを返し,イテレータを更新(次のノードに移動)します.つまり,この関数の動作は,通常のC言語のポインタでの text 表現,あるいはC++のコレクションのイテレータとほぼ同じです.また,それ以上のノードがない場合は,NULL を返します.
cv::PrevTreeNode¶
- void* cvPrevTreeNode(CvTreeNodeIterator* tree_iterator)¶
現在の対象ノードを返し,イテレータを前のノードに戻します.
Parameter: tree_iterator – 木ノード用のイテレータ
この関数は,現在の対象ノードを返し,イテレータを更新(前のノードに移動)します.つまり,この関数の動作は,通常のC言語のポインタでの *p-- 表現,あるいはC++のコレクションのイテレータとほぼ同じです.また,それ以上のノードがない場合は,NULL を返します.
cv::ReleaseGraphScanner¶
- void cvReleaseGraphScanner(CvGraphScanner** scanner)¶
グラフ走査処理を終了します.
Parameter: scanner – グラフの走査状態構造体へのダブルポインタ
この関数は,グラフの走査処理を完了させ,走査状態構造体を解放します.
cv::ReleaseMemStorage¶
- void cvReleaseMemStorage(CvMemStorage** storage)¶
メモリストレージを解放します.
Parameter: storage – 解放するストレージへのポインタ
この関数は,ストレージ内の全てのメモリブロックを解放します.あるいは,親メモリストレージが存在すれば,そこにメモリ領域を返します.その際,ストレージヘッダも解放され,ストレージへのポインタはクリアされます.親ストレージブロックが解放される前に,それに関連する全ての子メモリストレージが解放されていなければいけません.
cv::RestoreMemStoragePos¶
- void cvRestoreMemStoragePos(CvMemStorage* storage, CvMemStoragePos* pos)¶
メモリストレージの先頭の位置を復元します.
パラメタ: - storage – メモリストレージ
- pos – ストレージの新しい先頭の位置
この関数は,引数 pos で与えられたストレージの先頭位置を復元します.これと関数 cvClearMemStorage だけが,ストレージブロック内の占有されたメモリを解放するための方法です.ストレージブロック内の占有された領域を,一部だけ解放する方法はないので注意してください.
cv::SaveMemStoragePos¶
- void cvSaveMemStoragePos(const CvMemStorage* storage, CvMemStoragePos* pos)¶
メモリストレージの先頭の位置を保存します.
パラメタ: - storage – メモリストレージ
- pos – 出力,メモリストレージの先頭の位置
この関数は,ストレージの先頭の現在位置を pos に出力します.なお,関数 cvRestoreMemStoragePos は,この位置を復元することができます.
cv::SeqElemIdx¶
- int cvSeqElemIdx(const CvSeq* seq, const void* element, CvSeqBlock** block=NULL)¶
指定されたシーケンス要素のインデックスを返します.
パラメタ: - seq – シーケンス
- element – シーケンス内部の要素へのポインタ
- block – オプション.このポインタが NULL でなければ,指定要素を含むシーケンスブロックのアドレスがこの場所に格納されます
この関数は,シーケンス要素のインデックスを返します.また,要素が見つからない場合は負の値を返します.
cv::SeqInsert¶
- char* cvSeqInsert(CvSeq* seq, int beforeIndex, void* element=NULL)¶
シーケンス中に要素を挿入します.
パラメタ: - seq – シーケンス
- beforeIndex – このインデックスの場所の直前に要素が挿入されます. 0 (指定可能なパラメータの最小値)の前への挿入する事は SeqPushFront と等価であり, seq->total (指定可能なパラメータの最大値)の前への挿入は SeqPush と等価です
- element – 挿入される要素
この関数は,指定した挿入位置から近い側の端までのシーケンス要素をシフトし, element で指定された要素を(そのポインタが NULL でなければ)指定位置にコピーします.この関数は,挿入された要素へのポインタを返します.
cv::SeqInsertSlice¶
- void cvSeqInsertSlice(CvSeq* seq, int beforeIndex, const CvArr* fromArr)¶
シーケンスの中に配列を挿入します.
パラメタ: - seq – シーケンス
- beforeIndex – 配列が挿入される場所へのインデックス(このインデックスの前に挿入されます)
- fromArr – 追加される配列
この関数は, fromArr の全ての配列要素をシーケンスの指定された位置に挿入します.配列 fromArr は,行列でも別のシーケンスでも構いません.
cv::SeqInvert¶
この関数は,入力シーケンスの要素の順序を(先頭の要素は末尾に,末尾の要素は先頭へ,という風に)反転させます.
cv::SeqPop¶
- void cvSeqPop(CvSeq* seq, void* element=NULL)¶
シーケンスの末尾から要素を削除します.
パラメタ: - seq – シーケンス
- element – オプション.このポインタが 0 でなければ,削除される要素はこの場所にコピーされます
この関数は,シーケンスの末尾から要素を取り除きます.シーケンスが既に空の場合にはエラーになります.また,この関数の計算量は, O(1) です.
cv::SeqPopFront¶
- void cvSeqPopFront(CvSeq* seq, void* element=NULL)¶
シーケンスの先頭から要素を削除します.
パラメタ: - seq – シーケンス
- element – オプション.このポインタが 0 でなければ,削除される要素はこの場所にコピーされます
この関数は,シーケンスの先頭から要素を取り除きます.シーケンスが既に空の場合にはエラーになります.また,この関数の計算量は, O(1) です.
cv::SeqPopMulti¶
- void cvSeqPopMulti(CvSeq* seq, void* elements, int count, int in_front=0)¶
複数の要素をシーケンスのどちらかの端(先頭か末尾)から削除します.
パラメタ: - seq – シーケンス
- elements – 削除される要素
- count – 削除される要素の個数
- in_front –
どちら側から要素が削除されるかを示すフラグ.
- CV_BACK シーケンスの末尾に要素が削除されます
- CV_FRONT シーケンスの先頭に要素が削除されます
この関数は,複数の要素をシーケンスのどちらかの端(先頭か末尾)から削除します.もし,削除される要素の個数がシーケンスの要素の総数を上回っている場合,可能な限りの要素が削除されます.
cv::SeqPush¶
- char* cvSeqPush(CvSeq* seq, void* element=NULL)¶
シーケンスの末尾に要素を追加します.
パラメタ: - seq – シーケンス
- element – 追加される要素
この関数は,シーケンス末尾に要素を追加し,その追加された要素へのポインタを返します. element が NULL の場合は,単に要素1個分の領域を確保します.
以下に,この関数を利用して新しいシーケンスを作成するコードを示します:
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* seq = cvCreateSeq( CV_32SC1, /* 整数型要素を持つシーケンス */
sizeof(CvSeq), /* ヘッダサイズ - 拡張フィールドなし */
sizeof(int), /* 要素サイズ */
storage /* シーケンスが入るストレージ */ );
int i;
for( i = 0; i < 100; i++ )
{
int* added = (int*)cvSeqPush( seq, &i );
printf( "
}
...
/* 最後にメモリストレージを解放します. */
cvReleaseMemStorage( &storage );
この関数の計算量は O(1) ですが,巨大なシーケンスを書き込む場合は,より高速な手法が存在します(関数 StartWriteSeq と,その関連関 数を参照してください).
cv::SeqPushFront¶
- char* cvSeqPushFront(CvSeq* seq, void* element=NULL)¶
シーケンスの先頭に要素を追加します.
パラメタ: - seq – シーケンス
- element – 追加される要素
この関数は, SeqPush と似ていますが,こちらはシーケンスの先頭に要素を追加します.また,この関数の計算量は, O(1) です.
cv::SeqPushMulti¶
- void cvSeqPushMulti(CvSeq* seq, void* elements, int count, int in_front=0)¶
複数の要素をシーケンスのどちらかの端(先頭か末尾)に追加します.
パラメタ: - seq – シーケンス
- elements – 追加される要素
- count – 追加される要素の個数
- in_front –
どちら側に要素が追加されるかを示すフラグ.
- CV_BACK シーケンスの末尾に要素が追加されます
- CV_FRONT シーケンスの先頭に要素が追加されます
この関数は,複数の要素をシーケンスのどちらかの端(先頭か末尾)に追加します.要素は,入力配列内にある順番どおりに追加されますが,異なるシーケンスブロックに分割される可能性があります.
cv::SeqRemove¶
この関数は,指定のインデックス位置にある要素を削除します.インデックスが範囲外の場合はエラーになります.また,空のシーケンスから要素を削除しようとする事も,範囲外アクセスの特殊ケースです.この関数は,指定位置に近い側のシーケンスの端と index 番目(これは含まない)の要素の間に存在するシーケンス要素をシフトする事によって,要素を削除します.
cv::SeqRemoveSlice¶
- void cvSeqRemoveSlice(CvSeq* seq, CvSlice slice)¶
シーケンススライスを削除します.
パラメタ: - seq – シーケンス
- slice – 削除されるスライス
この関数は,シーケンスからシーケンススライスを削除します.
cv::SeqSearch¶
- char* cvSeqSearch(CvSeq* seq, const void* elem, CvCmpFunc func, int is_sorted, int* elem_idx, void* userdata=NULL)¶
シーケンス内の要素を検索します.
パラメタ: - seq – シーケンス
- elem – 検索される要素
- func – 要素同士の関係に応じて,負・0・正の値を返す比較関数( SeqSort も参照してください)
- is_sorted – シーケンスがソートされているかどうか,を表します
- elem_idx – 出力パラメータ.見つかった要素のインデックス
- userdata – 比較関数に渡されるユーザパラメータ.これによって,グローバル変数を使用せずにすむ場合があります
/* a < b ? -1 : a > b ? 1 : 0 */
typedef int (CV_CDECL* CvCmpFunc)(const void* a, const void* b, void* userdata);
この関数は,シーケンス内から指定された要素を見つけ出します.シーケンスがソートされていれば,O(log(N)) の二分探索法が用いられ,そうでなければ O(N) の単純な線形探索が用いられます.要素が見つからない場合は, NULLポインタを返します.線形探索を用いて見つからない場合は, elem_idx にはシーケンスの要素数がセットされます.二分探索を用いて見つからない場合は, i, seq(i)>elem を満たす最小のインデックスがセットされます.
cv::SeqSlice¶
- CvSeq* cvSeqSlice(const CvSeq* seq, CvSlice slice, CvMemStorage* storage=NULL, int copy_data=0)¶
シーケンススライスに対する別個のヘッダを作成します.
パラメタ: - seq – 入力シーケンス
- slice – 抽出されるシーケンスの一部(スライス)
- storage – 新しいシーケンスヘッダと,(もしあれば)コピーされたデータを保存する出力ストレージブロック.これが NULL の場合,入力シーケンスが存在するストレージブロックを使用します
- copy_data – 抽出されたスライスの要素をコピーするか( copy_data!=0 ),否か( copy_data=0 )を指定するフラグ
この関数は,指定されたシーケンススライスを表現するシーケンスを作成します.新しいシーケンスでは,その要素を元のシーケンスと共有するか,独自でそのコピーを持つかのいずれかです.シーケンスの一部だけを処理する必要があるが,その処理関数がスライスパラメータを持たない場合に,この関数を用いて必要なサブシーケンスを抽出することができます.
cv::SeqSort¶
/* a < b ? -1 : a > b ? 1 : 0 */
typedef int (CV_CDECL* CvCmpFunc)(const void* a, const void* b, void* userdata);
param seq: ソートされるシーケンス param func: 要素同士の関係に応じて,負・0・正の値を返す比較関数(上記の宣言と,下の例を参照してください).C言語の qsort でも,最後の引数 userdata がない事以外は同様の関数が利用されます param userdata: 比較関数に渡されるユーザパラメータ.これによって,グローバル変数を使用せずにすむ場合があります
この関数は,指定された基準に基づいてシーケンスをソートします.以下は,その使用例です:
/* 2次元の点を上から下,左から右に並ぶようにソートします. */
static int cmp_func( const void* _a, const void* _b, void* userdata )
{
CvPoint* a = (CvPoint*)_a;
CvPoint* b = (CvPoint*)_b;
int y_diff = a->y - b->y;
int x_diff = a->x - b->x;
return y_diff ? y_diff : x_diff;
}
...
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* seq = cvCreateSeq( CV_32SC2, sizeof(CvSeq), sizeof(CvPoint), storage );
int i;
for( i = 0; i < 10; i++ )
{
CvPoint pt;
pt.x = rand()
pt.y = rand()
cvSeqPush( seq, &pt );
}
cvSeqSort( seq, cmp_func, 0 /* userdata is not used here */ );
/* ソートされたデータを出力します. */
for( i = 0; i < seq->total; i++ )
{
CvPoint* pt = (CvPoint*)cvSeqElem( seq, i );
printf( "(
}
cvReleaseMemStorage( &storage );
cv::SetAdd¶
- int cvSetAdd(CvSet* setHeader, CvSetElem* elem=NULL, CvSetElem** inserted_elem=NULL)¶
セットのノードを占有(ノードを追加)します.
パラメタ: - set_header – セット
- elem – オプション.挿入される要素.これが NULL 以外ならば,関数は確保されたノードにこのデータをコピーします(最初の整数型フィールドの最上位ビットは,コピー後にクリアされます)
- inserted_elem – オプション.確保されたノードへのポインタ
この関数は,新しいノードを確保し,(与えられていれば)入力要素データをそこにコピーします.そして,そのノードへのポインタとインデックスを返します.インデックスの値は,そのノードのフィールド flags の下位ビットから取得します.なお,計算量は O(1) ですが,セットのノードを確保するためのより高速な関数も存在します( SetNew を参照してください).
cv::SetNew¶
この関数は, SetAdd をインライン処理した高速版です.これは新しいノードを確保し,インデックスではなくノードへのポインタを返します.
cv::SetRemove¶
- void cvSetRemove(CvSet* setHeader, int index)¶
セットからノードを削除します.
パラメタ: - setHeader – セット
- index – 削除されるノードのインデックス
この関数は,インデックスで指定したノードをセットから削除します.指定した場所のノードが空だった場合,この関数は何もしません.なお,計算量は O(1) ですが,既に取り除く要素の場所が既知である場合は, SetRemoveByPtr の方が高速です.
cv::SetRemoveByPtr¶
- void cvSetRemoveByPtr(CvSet* setHeader, void* elem)¶
ポインタが示すノードをセットから削除します.
パラメタ: - setHeader – セット
- elem – 削除されるノード
この関数は, SetRemove をインライン処理した高速版であり,ノードの指定にそのポインタを利用します.また,この関数はノードが使用されているかどうかをチェックしないので,ユーザは注意して使う必要があります.
cv::SetSeqBlockSize¶
- void cvSetSeqBlockSize(CvSeq* seq, int deltaElems)¶
シーケンスのブロックサイズを設定します.
パラメタ: - seq – シーケンス
- deltaElems – 要素数単位で表された,シーケンスのブロックサイズ
この関数は,メモリ確保の粒度に影響を与えます.シーケンス内の利用可能領域がなくなった場合, deltaElems 個の要素に対して新たにメモリが確保されます.このブロックが以前に確保したものの直後であれば,その 2つのブロックは統合され,そうでなければ,新しいブロックが作成されます.したがって,このパラメータが大きくなるほどシーケンスの断片化は抑えられますが,ストレージブロックの中の多くの領域が消費されることになります.シーケンス作成時には,パラメータ deltaElems はデフォルトである約 1K の値に設定されます.シーケンス作成後は,いつでもこの関数を呼ぶことができ,以降のメモリ確保の際にその値が使われます.この関数を用いることで,使用メモリの制限に合わせてパラメータを変更できます.
cv::SetSeqReaderPos¶
- void cvSetSeqReaderPos(CvSeqReader* reader, int index, int is_relative=0)¶
リーダを指定位置に移動します.
パラメタ: - reader – リーダ状態構造体
- index – 目標位置.位置モード(次のパラメータを参照してください)が使われる場合, index mod reader->seq->total が実際の位置になります
- is_relative – これが 0 でない場合, index は現在位置に対する相対位置を表します
この関数は,指定された絶対位置,あるいは現在の位置に対する相対位置まで,リーダの読み込み位置を移動します.
cv::StartAppendToSeq¶
- void cvStartAppendToSeq(CvSeq* seq, CvSeqWriter* writer)¶
シーケンスへのデータ書き込み処理を初期化します.
パラメタ: - seq – シーケンスへのポインタ
- writer – この関数によって初期化されるライタ状態構造体
この関数は,シーケンスへのデータ書き込み処理を初期化します.書き込まれる要素は,マクロ CV_WRITE_SEQ_ELEM( written_elem, writer ) によってシーケンスの最後に追加されます.書き込み処理中にシーケンスに対して他の処理が行われると,誤った結果になったりシーケンス自体が壊れたりする可能性があることに注意してください(このような問題を回避するには FlushSeqWriter の説明を参照してください).
cv::StartReadSeq¶
- void cvStartReadSeq(const CvSeq* seq, CvSeqReader* reader, int reverse=0)¶
シーケンスからの連続読み出し処理を初期化します.
パラメタ: - seq – シーケンス
- reader – この関数で初期化されるリーダ状態構造体
- reverse – シーケンスの走査方向の指定. reverse が 0 ならばリーダはシーケンスの先頭要素,そうでなければ末尾要素に位置します
この関数は,リーダ状態構造体を初期化します.続いて,順方向読み出しの場合は,マクロ CV_READ_SEQ_ELEM( read_elem, reader ) を順次呼び出すことで,シーケンスの全要素が先頭から末尾に向かって読み出されます.また,逆方向読み出しの場合は,代わりにマクロ CV_REV_READ_SEQ_ELEM( read_elem, reader ) を利用します.どちらのマクロでも,シーケンス要素が read_elem に出力され,読み出しポインタが次の要素に移動されます.この読み出し処理でも,シーケンスブロックの循環構造が利用されます.つまり,マクロ CV_READ_SEQ_ELEM によって最後の要素が読み出された後に,再びこのマクロが呼ばれると,最初の要素が読み込まれます.これは,マクロ CV_REV_READ_SEQ_ELEM の場合も同様です.シーケンスの変更もテンポラリバッファの作成も行わないので,読み出し処理を終了するための関数はありません.リーダのフィールド ptr は,次に読み込まれる予定の,シーケンスの現在の要素を指します.以下のコードで,シーケンスリーダとライタの使い方を示します.
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* seq = cvCreateSeq( CV_32SC1, sizeof(CvSeq), sizeof(int), storage );
CvSeqWriter writer;
CvSeqReader reader;
int i;
cvStartAppendToSeq( seq, &writer );
for( i = 0; i < 10; i++ )
{
int val = rand()
CV_WRITE_SEQ_ELEM( val, writer );
printf("
}
cvEndWriteSeq( &writer );
cvStartReadSeq( seq, &reader, 0 );
for( i = 0; i < seq->total; i++ )
{
int val;
#if 1
CV_READ_SEQ_ELEM( val, reader );
printf("
#else /* 代替手段,シーケンスの要素数が多い場合や,コンパイル時に
サイズや型がわからない場合はこの方法が望ましいです */
printf("
CV_NEXT_SEQ_ELEM( seq->elem_size, reader );
#endif
}
...
cvReleaseStorage( &storage );
cv::StartWriteSeq¶
- void cvStartWriteSeq(int seq_flags, int header_size, int elem_size, CvMemStorage* storage, CvSeqWriter* writer)¶
新しいシーケンスを作成し,そのためのライタを初期化します.
パラメタ: - seq_flags – 作成するシーケンスのフラグ.決まった種類のシーケンスだけを処理する関数に渡されるのでなければ,この値を 0 にしても構いません.そうでなければ,定義済みシーケンスのリストから適切な種類を選択する必要があります
- header_size – シーケンスヘッダのサイズ. sizeof(CvSeq) 以上でなければいけません.また,特定の種類やそれを拡張したものが指定される場合,それは基本型ヘッダと矛盾してはいけません
- elem_size – バイト単位で表されるシーケンスの要素サイズ.このサイズはシーケンスの型と矛盾してはいけません.例えば,点群のシーケンスを作成する場合,要素の種類は CV_SEQ_ELTYPE_POINT であり,シーケンスのパラメータ elem_size は sizeof(CvPoint) と等しくなければいけません
- storage – シーケンスが格納されているストレージ
- writer – この関数によって初期化されるライタ状態構造体
この関数は, CreateSeq と StartAppendToSeq を組み合わせたものです.作成されたシーケンスへのポインタは writer->seq に格納されます.これは,書き込み処理の最後に呼び出されるべき関数 EndWriteSeq によっても返されます.
cv::TreeToNodeSeq¶
- CvSeq* cvTreeToNodeSeq(const void* first, int header_size, CvMemStorage* storage)¶
全ノードへのポインタを1つのシーケンスにまとめます.
パラメタ: - first – 先頭の木ノード
- header_size – 作成されるシーケンスのヘッダサイズ( sizeof(CvSeq) が最もよく利用される値です)
- storage – シーケンスの格納場所
この関数は,先頭のノード first から到達可能なすべてのノードへのポインタを,1つのシーケンスにまとめます.これらのポインタは,深さ優先順で書き込まれます.
ヘルプとフィードバック
お探しの情報が見つかりませんか?- FAQ (英語)を試してください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はopencv.jpまでお願い します.
![]()
目次
- 動的構造体
- CvMemStorage
- CvMemBlock
- CvMemStoragePos
- CvSeq
- CvSeqBlock
- CvSlice
- CvSet
- CvGraph
- CvGraphScanner
- CvTreeNodeIterator
- cv::ClearGraph
- cv::ClearMemStorage
- cv::ClearSeq
- cv::ClearSet
- cv::CloneGraph
- cv::CloneSeq
- cv::CreateChildMemStorage
- cv::CreateGraph
- cv::CreateGraphScanner
- cv::CreateMemStorage
- cv::CreateSeq
- cv::CreateSet
- cv::CvtSeqToArray
- cv::EndWriteSeq
- cv::FindGraphEdge
- cv::FindGraphEdgeByPtr
- cv::FlushSeqWriter
- cv::GetGraphVtx
- cv::GetSeqElem
- cv::GetSeqReaderPos
- cv::GetSetElem
- cv::GraphAddEdge
- cv::GraphAddEdgeByPtr
- cv::GraphAddVtx
- cv::GraphEdgeIdx
- cv::GraphRemoveEdge
- cv::GraphRemoveEdgeByPtr
- cv::GraphRemoveVtx
- cv::GraphRemoveVtxByPtr
- cv::GraphVtxDegree
- cv::GraphVtxDegreeByPtr
- cv::GraphVtxIdx
- cv::InitTreeNodeIterator
- cv::InsertNodeIntoTree
- cv::MakeSeqHeaderForArray
- cv::MemStorageAlloc
- cv::MemStorageAllocString
- cv::NextGraphItem
- cv::NextTreeNode
- cv::PrevTreeNode
- cv::ReleaseGraphScanner
- cv::ReleaseMemStorage
- cv::RestoreMemStoragePos
- cv::SaveMemStoragePos
- cv::SeqElemIdx
- cv::SeqInsert
- cv::SeqInsertSlice
- cv::SeqInvert
- cv::SeqPop
- cv::SeqPopFront
- cv::SeqPopMulti
- cv::SeqPush
- cv::SeqPushFront
- cv::SeqPushMulti
- cv::SeqRemove
- cv::SeqRemoveSlice
- cv::SeqSearch
- cv::SeqSlice
- cv::SeqSort
- cv::SetAdd
- cv::SetNew
- cv::SetRemove
- cv::SetRemoveByPtr
- cv::SetSeqBlockSize
- cv::SetSeqReaderPos
- cv::StartAppendToSeq
- cv::StartReadSeq
- cv::StartWriteSeq
- cv::TreeToNodeSeq