クラスタリングと多次元空間探索¶
cv::kmeans¶
- double kmeans(const Mat& samples, int clusterCount, Mat& labels, TermCriteria termcrit, int attempts, int flags, Mat* centers)¶
クラスタ中心を求め,入力サンプルを各クラスタにグループ分けします.
パラメタ: - samples – 入力サンプルの浮動小数点型行列.1行が1つのサンプルを表します
- clusterCount – サンプル集合を分割するクラスタ数
- labels – 整数型の入出力配列.各要素が属するクラスタのインデックスを格納します
- termcrit – 反復数の最大値 および/または 精度(連続する試行間でクラスタ中心が移動する距離)を指定します
- attempts – このアルゴリズムが,異なる初期ラベルを与えられて実行される回数.このアルゴリズムは,最もコンパクトな分割を行うラベル(最後のパラメータを参照してください)を返します
- flags –
以下の値をとることができます:
- KMEANS_RANDOM_CENTERS 各試行で,ランダムな初期中心が選択されます
- KMEANS_PP_CENTERS Arthur および Vassilvitskiiによる kmeans++ の中心初期化手法が利用されます
- KMEANS_USE_INITIAL_LABELS 最初の試行で(だけ)は,ランダムに生成されるラベルの代わりに,ユーザが与えたラベルを初期推定値として利用します.2回目以降の試行では,ランダムまたは半ランダム(手法を指定するために KMEANS_*_CENTERS フラグの1つを利用します)に選択された中心が用いられます
- centers – クラスタ中心の出力行列.1つの行が1つのクラスタ中心を表します
関数
kmeans
は,
clusterCount
個のクラスタの中心を求め,入力サンプルを各クラスタに分類する k-means アルゴリズムの実装です.出力として,
samples
行列の
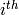 行目のサンプルが属するクラスタの(0基準の)インデックスが,
行目のサンプルが属するクラスタの(0基準の)インデックスが,
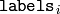 に格納されます.
に格納されます.
この関数は,次のように計算されるコンパクト尺度を返します.
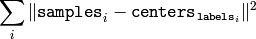
全試行の終了後,最もよい(小さい)値が選択され,それに対応するラベルとコンパクト尺度が戻り値として返されます.
また,基本的に次のようにして,ユーザはこの関数の基本機能だけを利用することができます.まず,試行回数を1にセットし,フラグ( flags = KMEANS_USE_INITIAL_LABELS )をセットして,独自アルゴリズムによりラベルを毎回初期化します そして,最良の(最もコンパクトな)クラスタリングを選択します.
cv::partition¶
- template<typename _Tp, class _EqPredicate> int()¶
- partition(const vector<_Tp>& vec, vector<int>& labels, _EqPredicate predicate=_EqPredicate())¶
要素の集合を同値クラス(同値類)に分割します.
パラメタ: - vec – ベクトルで表現された要素の集合
- labels – 出力されるラベルのベクトル. vec と同じ要素数.各ラベル labels[i] は, vec[i] が属する0基準のクラスタインデックスです
- predicate – 同値述語(つまり,2つの引数をとり真偽値を返す関数へのポインタ,あるいは, bool operator()(const _Tp& a, const _Tp& b) メソッドを持つクラスのインスタンスへのポインタ).この述語は,要素が確実に同じクラスならば真値を返し,同じクラスの可能性がある(同じクラスではない可能性がある)場合は偽値を返します
汎用関数
partition
は,
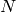 個の要素の集合を1つまたは複数の同値類に分割する
個の要素の集合を1つまたは複数の同値類に分割する
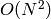 のアルゴリズムの実装です.これについては
http://en.wikipedia.org/wiki/Disjoint-set_data_structure
で説明されています.また,この関数は,同値類の個数を返します.
のアルゴリズムの実装です.これについては
http://en.wikipedia.org/wiki/Disjoint-set_data_structure
で説明されています.また,この関数は,同値類の個数を返します.
K-近傍探索の高速な近似計算¶
このセクションでは,OpenCV の FLANN ライブラリインタフェースについて説明します.FLANN(Fast Library for Approximate Nearest Neighbors)は,巨大なデータセットと高次元特徴に対する K-近傍探索の高速な近似計算に最適化されたアルゴリズムのコレクションです.FLANN についてさらに詳しく知りたい場合は, muja_flann_2009 を参照してください.
flann::Index¶
- flann::Index¶
FLANN 最近傍インデックスクラス
namespace flann
{
class Index
{
public:
Index(const Mat& features, const IndexParams& params);
void knnSearch(const vector<float>& query,
vector<int>& indices,
vector<float>& dists,
int knn,
const SearchParams& params);
void knnSearch(const Mat& queries,
Mat& indices,
Mat& dists,
int knn,
const SearchParams& params);
int radiusSearch(const vector<float>& query,
vector<int>& indices,
vector<float>& dists,
float radius,
const SearchParams& params);
int radiusSearch(const Mat& query,
Mat& indices,
Mat& dists,
float radius,
const SearchParams& params);
void save(std::string filename);
int veclen() const;
int size() const;
};
}
cv::flann::Index::Index¶
- Index::Index(const Mat& features, const IndexParams& params)¶
与えられたデータセットの最近傍探索インデックスを作成します.
パラメタ: - features – インデックス作成対象となる特徴(点)が格納された, CV_32F 型の行列.この行列のサイズは matrix is num _ features x feature _ dimensionality となります
- params – インデックスパラメータを含む構造体.作成されるインデックスの種類は,このパラメータの種類に依存します
選択できるパラメータの種類を以下に示します:
LinearIndexParams この型のオブジェクトが渡されると,インデックスは線形になり,ブルートフォース探索されます.
cvcode
KDTreeIndexParams この型のオブジェクトが渡されると,並列に探索されるランダム kd-tree の集合でインデックスが表現されます.
cvcode
- trees 並列な kd-tree の個数.[1..16] の範囲が適切な値です
- KMeansIndexParams この型のオブジェクトが渡されると,階層型 k-means tree でインデックスが表現されます.
cvcode
- branching 階層型 k-means tree で利用される branching ファクタ
- iterations k-means tree を作成する際の,k-means クラスタリング段階での反復数の上限.ここで -1 は,k-means クラスタリングが収束するまで続けられることを意味します
- centers_init k-means クラスタリングの初期中心を選択するアルゴリズム.CENTERS _ RANDOM(ランダムに初期クラスタ中心を選択), CENTERS _ GONZALES(Gonzalesのアルゴリズムを用いて初期クラスタ中心を選択), CENTERS _ KMEANSPP( arthur_kmeanspp_2007 で提案されたアルゴリズムを用いて初期クラスタ中心を選択)のいずれかです
- cb_index このパラメータ(クラスタ境界インデックス)は,階層的 k-means tree の探索方法に影響を与えます. cb_index が0の場合,最も近い中心のクラスタが,次に探索される k-means 領域になります.0より大きい値の場合も,領域サイズが考慮されます
CompositeIndexParams この型のパラメータオブジェクトを利用すると,ランダム kd-tree と 階層的 k-means tree の組み合わせでインデックスが表現されます.
cvcode
AutotunedIndexParams この型のオブジェクトが渡されると,与えられたデータ集合に対して最適なインデックスの種類(ランダム kd-tree,階層的 k-means tree,線形)とパラメータが選択され,最も効率的になるように自動で調整されたインデックスが作成されます.
cvcode
- target_precision どれだけ厳密な最近傍を返すかという,最近傍探索の近似の割合を指定する 0から1の間の値.このパラメータが大きくなると,より正確な結果が得られますが,探索時間が長くなります.最適な値は,アプリケーションに依存します
- build_weight 最近傍探索時間に対するインデックスの構築時間の重要度を指定します.その後のインデックス探索時間が高速になるならば,インデックスの構築時間が長くても良いというアプリケーションが存在する一方で,インデックスの探索時間が多少長くなっても,できるだけ高速にインデックスを構築する必要があるアプリケーションもあります
- memory_weight これは,(インデックスの構築時間と探索時間)とインデックスの占有メモリとの,トレードオフを指定するのに利用されます.1より小さい値は消費時間を重要視し,1より大きい値はメモリ使用量を重要視します
- sample_fraction パラメータの自動設定アルゴリズムにおけるデータ集合の比率を示す,0から1の間の値.全データ集合を用いてアルゴリズムを実行すると,最も正確な結果が得られますが,巨大なデータ集合に対しては長い計算時間がかかります.このような場合,データをある比率分だけ使うことでアルゴリズムを高速化し,なおかつ,最適なパラメータの良い近似となる結果を得ることができます
- SavedIndexParams この型のオブジェクトは,ディスクにあらかじめ保存されたデータを読み出すために利用されます.
cvcode
- filename インデックスが保存されたファイル名
cv::flann::Index::knnSearch¶
- void Index::knnSearch(const vector<float>& query, vector<int>& indices, vector<float>& dists, int knn, const SearchParams& params)¶
インデックスを用いてクエリ点に対するk-近傍探索を行います.
パラメタ: - query – クエリ点
- indices – k-近傍探索で求められたインデックスが格納されるベクトル.最低でも knn サイズでなければいけません
- dists – k-近傍探索で求められた距離が格納されるベクトル.最低でも knn サイズでなければいけません
- knn – この個数分の最近傍を求めます
- params – 探索パラメータ
struct SearchParams { SearchParams(int checks = 32); };
- checks インデックスの tree が再帰的に横断されるべき回数.このパラメータが大きくなると,より正確な探索が行われますが,探索時間も長くなります.インデックス作成時に自動設定が利用されると,指定精度を達成するために必要な checks 数も計算されます.その場合,このパラメータは無視されます
cv::flann::Index::knnSearch¶
cv::flann::Index::radiusSearch¶
- int Index::radiusSearch(const vector<float>& query, vector<int>& indices, vector<float>& dists, float radius, const SearchParams& params)¶
与えられたクエリ点に対するradius 最近傍探索を行います.
パラメタ: - query – クエリ点
- indices – 探索範囲内に存在する近傍点のインデックスが格納されるベクトル.クエリ点までの距離で降順に並びます.探索範囲内の近傍数がこのベクトルサイズよりも大きい場合,はみ出したものは無視されます
- dists – 探索範囲内に存在する近傍点までの距離が格納されるベクトル
- radius – 探索範囲
- params – 探索パラメータ
cv::flann::Index::radiusSearch¶
cv::flann::Index::save¶
- void Index::save(std::string filename)¶
インデックスをファイルに保存します.
Parameter: filename – インデックスを保存するファイル名
cv::flann::hierarchicalClustering¶
- int hierarchicalClustering(const Mat& features, Mat& centers, const KMeansIndexParams& params)¶
階層的 k-means tree を構築し,クラスタの分散を最小にするカットを選択することで,与え得られた点群を分類します.
パラメタ: - features – クラスタリングされる点
- centers – 得られるクラスタの中心.この行列の行数は要求クラスタ数を表します.しかし,階層的 k-means tree のカットを選択する方法により,求められるクラスタ数は,要求クラスタ数より小さい値
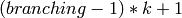 の最大値になります.ここで
の最大値になります.ここで 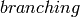 は tree の branching ファクタ(KMeansIndexParams の説明を参照してください)
は tree の branching ファクタ(KMeansIndexParams の説明を参照してください) - params – 階層的 k-means tree を構築する際に利用されるパラメータ
このメソッドは,求められたクラスタ数を返します.
ヘルプとフィードバック
お探しの情報が見つかりませんか?- FAQ (英語)を試してください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はopencv.jpまでお願い します.