物体検出¶
cv::MatchTemplate¶
- MatchTemplate(image, templ, result, method) → None¶
テンプレートと,それと重なる領域の画像とを比較します.
パラメタ:
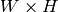 で,
で, 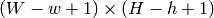 となります
となりますこの関数は,
CalcBackProjectPatch
と類似した関数です.画像
image
全体に対してテンプレート
templ
をずらしながら,それとサイズ
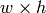 の重なり領域とを指定された方法で比較し,その結果を
result
に格納します.ここでは,それぞれの比較手法の式を示します(
の重なり領域とを指定された方法で比較し,その結果を
result
に格納します.ここでは,それぞれの比較手法の式を示します(
 は
image
,
は
image
,
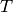 は
template
,
は
template
,
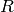 は
result
を表します).総和演算は,テンプレートと重なり領域の,どちらか片方あるいは両方に対して行われます:
は
result
を表します).総和演算は,テンプレートと重なり領域の,どちらか片方あるいは両方に対して行われます:
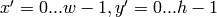
method=CV_TM_SQDIFF
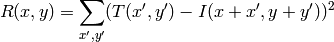
method=CV_TM_SQDIFF_NORMED
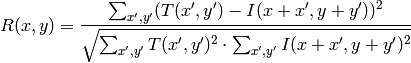
method=CV_TM_CCORR
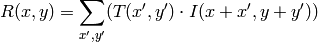
method=CV_TM_CCORR_NORMED
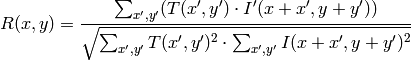
method=CV_TM_CCOEFF
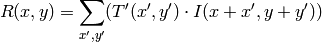
ここで,
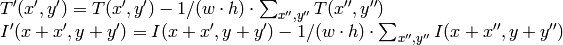
です.
method=CV_TM_CCOEFF_NORMED
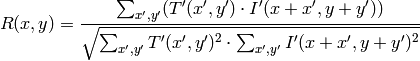
比較計算が終わると,関数 MinMaxLoc を用いて最も良いマッチング結果を,最小値( CV_TM_SQDIFF )や最大値( CV_TM_CCORR )として検出できます.カラー画像の場合,分母や分子のそれぞれの総和演算は,全てのチャンネルに対して行われます(それぞれチャンネルで,それぞれの平均値が用いられます).
物体検出のための Haar 特徴に基づくカスケード分類器¶
ここで述べられる物体検出器は, Paul Viola
Viola01
によって最初に提案され,Rainer Lienhart
Lienhart02
によって改良されたものです.まず,分類器(つまり,
haar-like特徴を用いるブースティングされた分類器のカスケード
)は,数百の正例と負例によって学習されます. 正例とは,同一のサイズ(例えば,
 )にスケーリングされた特定の物体(つまり,顔や車)を含むサンプル画像であり,負例とは,正例と同一サイズの任意の画像です.
)にスケーリングされた特定の物体(つまり,顔や車)を含むサンプル画像であり,負例とは,正例と同一サイズの任意の画像です.
学習が終わると,分類器は入力画像の(学習に用いられた物と同じサイズの)ROI に対して適用されます.その領域に物体(顔や車)が写っていると思われる場合は,分類器は「1」を出力し,それ以外では,「0」を出力します.画像全体から物体を探索するためには,画像中の探索窓を移動させながら,その個々の領域を分類器を用いて判別します.学習時とは異なるサイズの物体も検出できるように,分類器は簡単に「サイズ変更」できるように設計されており,これは画像自体のサイズを変更するよりも効率的です.そして,画像中からサイズ不明の物体を検出するためには,異なるスケールで複数回の探索処理が必要です.
分類器の名前にある「カスケード」という単語は,最終的に得られる分類器がいくつかの単純な分類器( stages )から構成される,という事を意味しています.この単純な分類器たちが ROI に対して次々に適用され,物体候補は,いずれかのステージで却下されるか,あるいは全てのステージを通過します.また,「ブーストされた」という単語は,カスケードの各ステージにおける単純な分類器自身が複合体である事を意味します.これらの単純な分類器は基本分類器から構成され,それには4種類の ブースティング 技法(重み付き投票)の内の1つが利用されます.現在のところ,Discrete Adaboost,Real Adaboost,Gentle Adaboost そして Logitboost がサポートされています.ここで利用される基本分類器は,少なくとも2つの葉を持つ決定木です. Haar-like 特徴はこの基本分類器の入力であり,その算出方法については後述します.現在のアルゴリズムでは次のような Haar-like 特徴を用いています:
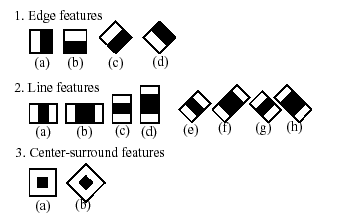
個々の分類器で用いられる特徴は,形状(1a, 2b など),ROI 内での位置,スケール(このスケールは検出ステージで用いられるスケールとは別物ですが,これら2つのスケールは乗じられます)によって規定されます.例えば,ライン特徴の3番目(2c)の場合,(2つの白ストライプと中央の黒ストライプを含む)特徴全体の矩形部分の画像ピクセルの和と,黒ストライプ部分の画像ピクセルの和を(領域サイズの違いを相殺するために)3倍したもの,との差分が出力となります.矩形領域全体のピクセル値の合計は,インテグラルイメージ(以下の説明,および Integral を参照してください)を用いて高速に計算されます.
顔検出の簡単なデモンストレーション.検出された顔の周りに矩形を描きます:
hc = cv.Load("haarcascade_frontalface_default.xml")
img = cv.LoadImage("faces.jpg", 0)
faces = cv.HaarDetectObjects(img, hc, cv.CreateMemStorage())
for (x,y,w,h),n in faces:
cv.Rectangle(img, (x,y), (x+w,y+h), 255)
cv.SaveImage("faces_detected.jpg", img)
cv::HaarDetectObjects¶
- HaarDetectObjects(image, cascade, storage, scale_factor=1.1, min_neighbors=3, flags=0, min_size=(0, 0)) → detected_objects¶
画像から物体検出を行います.
パラメタ: - image (CvArr) – この画像の中から物体を検出する
- cascade (CvHaarClassifierCascade) – Haar分類器カスケードの内部表現
- storage (CvMemStorage) – 物体候補の矩形列を保存するメモリストレージ
- scale_factor (float) – スキャン毎にスケーリングされる探索窓のスケーリングファクタ.たとえば,これが1.1ならば,探索窓が10 % 大きくなります
%–
パラメタ: - scale_factor (float) – The factor by which the search window is scaled between the subsequent scans, 1.1 means increasing window by 10 %
- min_neighbors (int) – (これから1を引いた値が)物体を表す矩形を構成する近傍矩形の最小数. min_neighbors -1 より少ない数の矩形しか含まないグループは,全て棄却されます. min_neighbors が0 の場合は,グループ化が行われずに,物体の候補となる個々の矩形が全て返されます.これは,ユーザが独自のグループ化処理を行いたい場合に有用です
- flags (int) – 処理モード.現在は, CV_HAAR_DO_CANNY_PRUNING のみ有効です.このフラグが指定されている場合,関数はCannyエッジ検出器を利用し,非常に多くのエッジを含む(あるいは非常に少ないエッジしか含まない)画像領域を,探索物体を含まない領域であると見なして棄却します.特定の閾値は顔検出用に調整されており,この場合,枝刈りにより処理が高速化されます
- min_size (CvSize) – 探索窓の最小サイズ.デフォルトでは,分類器の学習に用いられたサンプルのサイズが設定されます(顔検出の場合は
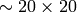 )
)
この関数は,与えられた画像から,カスケードの学習対象となった物体を含むであろう矩形領域を検出し,それらの領域を矩形のシーケンスとして返します.これは,画像のスキャンを異なるスケールで複数回行います(
SetImagesForHaarClassifierCascade
を参照してください).毎回,各スケールにあった画像領域を処理対象とし,
RunHaarClassifierCascade
を用いて,分類器をこの領域に適用します.また,判別する領域数を減らすために,Cannyエッジ検出器を用いた枝刈り処理のようなヒューリスティックな手法を適用することもあります.処理された物体候補矩形(分類器カスケードに渡された領域)が集められると,それらはグループ化され,さらに十分に大きいグループの平均矩形のみがシーケンスとして返されます.デフォルトパラメータ(
scale_factor
=1.1,
min_neighbors
=3,
flags
=0)は,正確ではあるが低速な物体検出用に調整されたものです.実際の動画像に対する,より高速な処理のためには,以下のような値が考えられます:
scale_factor
=1.2,
min_neighbors
=2,
flags
=
CV_HAAR_DO_CANNY_PRUNING
,
min_size
=
あり得る最小の顔サイズ
(例えばビデオ会議の場合は,画面全体の
 1/4 から 1/16 )
1/4 から 1/16 )
この関数は,タプル (rect, neighbors) のリストを返します.ここで, rect は物体の範囲を示す CvRect であり,また neighbors は隣接矩形の個数を示します.
>>> import cv
>>> image = cv.LoadImageM("lena.jpg", cv.CV_LOAD_IMAGE_GRAYSCALE)
>>> cascade = cv.Load("../../data/haarcascades/haarcascade_frontalface_alt.xml")
>>> print cv.HaarDetectObjects(image, cascade, cv.CreateMemStorage(0), 1.2, 2, 0, (20, 20))
[((217, 203, 169, 169), 24)]
ヘルプとフィードバック
お探しの情報が見つかりませんか?- FAQ (英語)を試してください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はopencv.jpまでお願い します.