Object Detection¶
MatchTemplate¶
- MatchTemplate(image, templ, result, method) → None¶
Compares a template against overlapped image regions.
Parameters: - image (CvArr) – Image where the search is running; should be 8-bit or 32-bit floating-point
- templ (CvArr) – Searched template; must be not greater than the source image and the same data type as the image
- result (CvArr) – A map of comparison results; single-channel 32-bit floating-point.
If image is
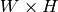 and templ is
and templ is 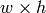 then result must be
then result must be 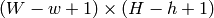
- method (int) – Specifies the way the template must be compared with the image regions (see below)
The function is similar to
CalcBackProjectPatch
. It slides through
image
, compares the
overlapped patches of size
against
templ
using the specified method and stores the comparison results to
result
. Here are the formulas for the different comparison
methods one may use (
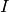 denotes
image
,
denotes
image
,
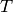 template
,
template
,
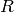 result
). The summation is done over template and/or the
image patch:
result
). The summation is done over template and/or the
image patch:
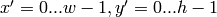
method=CV_TM_SQDIFF
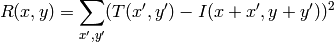
method=CV_TM_SQDIFF_NORMED
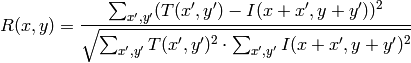
method=CV_TM_CCORR
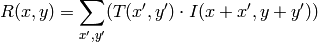
method=CV_TM_CCORR_NORMED
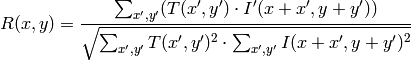
method=CV_TM_CCOEFF
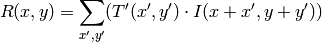
where
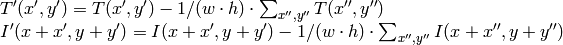
method=CV_TM_CCOEFF_NORMED
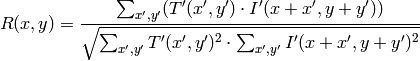
After the function finishes the comparison, the best matches can be found as global minimums ( CV_TM_SQDIFF ) or maximums ( CV_TM_CCORR and CV_TM_CCOEFF ) using the MinMaxLoc function. In the case of a color image, template summation in the numerator and each sum in the denominator is done over all of the channels (and separate mean values are used for each channel).
Haar Feature-based Cascade Classifier for Object Detection¶
The object detector described below has been initially proposed by Paul Viola Viola01 and improved by Rainer Lienhart Lienhart02 . First, a classifier (namely a cascade of boosted classifiers working with haar-like features ) is trained with a few hundred sample views of a particular object (i.e., a face or a car), called positive examples, that are scaled to the same size (say, 20x20), and negative examples - arbitrary images of the same size.
After a classifier is trained, it can be applied to a region of interest (of the same size as used during the training) in an input image. The classifier outputs a “1” if the region is likely to show the object (i.e., face/car), and “0” otherwise. To search for the object in the whole image one can move the search window across the image and check every location using the classifier. The classifier is designed so that it can be easily “resized” in order to be able to find the objects of interest at different sizes, which is more efficient than resizing the image itself. So, to find an object of an unknown size in the image the scan procedure should be done several times at different scales.
The word “cascade” in the classifier name means that the resultant classifier consists of several simpler classifiers ( stages ) that are applied subsequently to a region of interest until at some stage the candidate is rejected or all the stages are passed. The word “boosted” means that the classifiers at every stage of the cascade are complex themselves and they are built out of basic classifiers using one of four different boosting techniques (weighted voting). Currently Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost are supported. The basic classifiers are decision-tree classifiers with at least 2 leaves. Haar-like features are the input to the basic classifers, and are calculated as described below. The current algorithm uses the following Haar-like features:
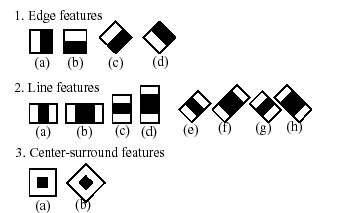
The feature used in a particular classifier is specified by its shape (1a, 2b etc.), position within the region of interest and the scale (this scale is not the same as the scale used at the detection stage, though these two scales are multiplied). For example, in the case of the third line feature (2c) the response is calculated as the difference between the sum of image pixels under the rectangle covering the whole feature (including the two white stripes and the black stripe in the middle) and the sum of the image pixels under the black stripe multiplied by 3 in order to compensate for the differences in the size of areas. The sums of pixel values over a rectangular regions are calculated rapidly using integral images (see below and the Integral description).
A simple demonstration of face detection, which draws a rectangle around each detected face:
hc = cv.Load("haarcascade_frontalface_default.xml")
img = cv.LoadImage("faces.jpg", 0)
faces = cv.HaarDetectObjects(img, hc, cv.CreateMemStorage())
for (x,y,w,h),n in faces:
cv.Rectangle(img, (x,y), (x+w,y+h), 255)
cv.SaveImage("faces_detected.jpg", img)
HaarDetectObjects¶
- HaarDetectObjects(image, cascade, storage, scale_factor=1.1, min_neighbors=3, flags=0, min_size=(0, 0)) → detected_objects¶
Detects objects in the image.
Parameters: - image (CvArr) – Image to detect objects in
- cascade (CvHaarClassifierCascade) – Haar classifier cascade in internal representation
- storage (CvMemStorage) – Memory storage to store the resultant sequence of the object candidate rectangles
- scale_factor (float) – The factor by which the search window is scaled between the subsequent scans, 1.1 means increasing window by 10 %
- min_neighbors (int) – Minimum number (minus 1) of neighbor rectangles that makes up an object. All the groups of a smaller number of rectangles than min_neighbors -1 are rejected. If min_neighbors is 0, the function does not any grouping at all and returns all the detected candidate rectangles, which may be useful if the user wants to apply a customized grouping procedure
- flags (int) – Mode of operation. Currently the only flag that may be specified is CV_HAAR_DO_CANNY_PRUNING . If it is set, the function uses Canny edge detector to reject some image regions that contain too few or too much edges and thus can not contain the searched object. The particular threshold values are tuned for face detection and in this case the pruning speeds up the processing
- min_size (CvSize) – Minimum window size. By default, it is set to the size of samples the classifier has been trained on (
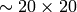 for face detection)
for face detection)
The function finds rectangular regions in the given image that are likely to contain objects the cascade has been trained for and returns those regions as a sequence of rectangles. The function scans the image several times at different scales (see
SetImagesForHaarClassifierCascade
). Each time it considers overlapping regions in the image and applies the classifiers to the regions using
RunHaarClassifierCascade
. It may also apply some heuristics to reduce number of analyzed regions, such as Canny prunning. After it has proceeded and collected the candidate rectangles (regions that passed the classifier cascade), it groups them and returns a sequence of average rectangles for each large enough group. The default parameters (
scale_factor
=1.1,
min_neighbors
=3,
flags
=0) are tuned for accurate yet slow object detection. For a faster operation on real video images the settings are:
scale_factor
=1.2,
min_neighbors
=2,
flags
=
CV_HAAR_DO_CANNY_PRUNING
,
min_size
=
minimum possible face size
(for example,
 1/4 to 1/16 of the image area in the case of video conferencing).
1/4 to 1/16 of the image area in the case of video conferencing).
The function returns a list of tuples, (rect, neighbors) , where rect is a CvRect specifying the object’s extents and neighbors is a number of neighbors.
>>> import cv
>>> image = cv.LoadImageM("lena.jpg", cv.CV_LOAD_IMAGE_GRAYSCALE)
>>> cascade = cv.Load("../../data/haarcascades/haarcascade_frontalface_alt.xml")
>>> print cv.HaarDetectObjects(image, cascade, cv.CreateMemStorage(0), 1.2, 2, 0, (20, 20))
[((217, 203, 169, 169), 24)]
Help and Feedback
You did not find what you were looking for?- Try the FAQ.
- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.