K-近傍法¶
このアルゴリズムでは,まず学習用サンプルをすべてキャッシュします.そして,新たなサンプルに対する応答を,その最近傍にある( K )個のサンプルを(投票や重み付き和などを用いて)分析し,予測します.この手法では,与えられたベクトルの近傍に存在する,応答が既知の特徴ベクトル,を調べて予測を行うので,「サンプルによる学習(learning by example)」と呼ばれることがあります.
CvKNearest¶
- CvKNearest¶
K-近傍法モデル.
class CvKNearest : public CvStatModel
{
public:
CvKNearest();
virtual ~CvKNearest();
CvKNearest( const CvMat* _train_data, const CvMat* _responses,
const CvMat* _sample_idx=0, bool _is_regression=false, int max_k=32 );
virtual bool train( const CvMat* _train_data, const CvMat* _responses,
const CvMat* _sample_idx=0, bool is_regression=false,
int _max_k=32, bool _update_base=false );
virtual float find_nearest( const CvMat* _samples, int k, CvMat* results,
const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0 ) const;
virtual void clear();
int get_max_k() const;
int get_var_count() const;
int get_sample_count() const;
bool is_regression() const;
protected:
...
};
CvKNearest::train¶
- bool CvKNearest::train(const CvMat* _train_data, const CvMat* _responses, const CvMat* _sample_idx=0, bool is_regression=false, int _max_k=32, bool _update_base=false)¶
モデルの学習を行います.
このメソッドは,K-近傍法のモデルの学習を行います.これは,以下の制限を持つ一般的な train 「メソッド」の形式に従います: CV_ROW_SAMPLE データレイアウトのみをサポートします.また,すべての入力変数は連続変数で,出力変数はカテゴリ変数( is_regression=false ),または連続変数( is_regression=true )です.変数(特徴)の部分集合,およびデータ欠損はサポートされません.
パラメータ _max_k は, find_nearest メソッドに渡されるであろう近傍の最大数を指定します.
パラメータ _update_base は,モデルを一から学習する( update_base=false )か,新しい学習データを利用して更新する( update_base=true )か,を指定します.後者の場合,パラメータ _max_k を,元の値よりも大きくしてはいけません.
CvKNearest::find_nearest¶
- float CvKNearest::find_nearest(const CvMat* _samples, int k, CvMat* results=0, const float** neighbors=0, CvMat* neighbor_responses=0, CvMat* dist=0) const¶
入力ベクトルの近傍を求めます.
(行列
_samples
の行である)各入力ベクトルに対して,このメソッドは,
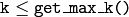 個の最近傍を求めます.回帰の場合,予測結果はそれぞれのベクトルの最近傍の平均値となります.分類の場合,投票によりクラスが決定されます.
個の最近傍を求めます.回帰の場合,予測結果はそれぞれのベクトルの最近傍の平均値となります.分類の場合,投票によりクラスが決定されます.
ユーザ独自の分類/回帰予測を行うために,このメソッドはオプションとして,近傍ベクトル自身へのポインタ( neighbors ,サイズ k*_samples->rows の配列)と,それに対応する出力値( neighbor_responses , k*_samples->rows 個の要素をもつベクトル),そして入力ベクトルからの近傍までの距離( dist , k*_samples->rows 個の要素をもつベクトル),を返すことができるようになっています.
それぞれの近傍は,各入力ベクトルまでの距離でソートされます.
また,単一の入力ベクトルが渡された場合,すべての出力行列はオプション扱いになり,このメソッドの戻り値が予測値なります.
#include "ml.h"
#include "highgui.h"
int main( int argc, char** argv )
{
const int K = 10;
int i, j, k, accuracy;
float response;
int train_sample_count = 100;
CvRNG rng_state = cvRNG(-1);
CvMat* trainData = cvCreateMat( train_sample_count, 2, CV_32FC1 );
CvMat* trainClasses = cvCreateMat( train_sample_count, 1, CV_32FC1 );
IplImage* img = cvCreateImage( cvSize( 500, 500 ), 8, 3 );
float _sample[2];
CvMat sample = cvMat( 1, 2, CV_32FC1, _sample );
cvZero( img );
CvMat trainData1, trainData2, trainClasses1, trainClasses2;
// 学習サンプルを生成します.
cvGetRows( trainData, &trainData1, 0, train_sample_count/2 );
cvRandArr( &rng_state, &trainData1, CV_RAND_NORMAL, cvScalar(200,200), cvScalar(50,50) );
cvGetRows( trainData, &trainData2, train_sample_count/2, train_sample_count );
cvRandArr( &rng_state, &trainData2, CV_RAND_NORMAL, cvScalar(300,300), cvScalar(50,50) );
cvGetRows( trainClasses, &trainClasses1, 0, train_sample_count/2 );
cvSet( &trainClasses1, cvScalar(1) );
cvGetRows( trainClasses, &trainClasses2, train_sample_count/2, train_sample_count );
cvSet( &trainClasses2, cvScalar(2) );
// 分類器を学習します.
CvKNearest knn( trainData, trainClasses, 0, false, K );
CvMat* nearests = cvCreateMat( 1, K, CV_32FC1);
for( i = 0; i < img->height; i++ )
{
for( j = 0; j < img->width; j++ )
{
sample.data.fl[0] = (float)j;
sample.data.fl[1] = (float)i;
// 応答を予測し,近傍のラベルを取得します.
response = knn.find_nearest(&sample,K,0,0,nearests,0);
// 多数を占める近傍の個数を求めます.
for( k = 0, accuracy = 0; k < K; k++ )
{
if( nearests->data.fl[k] == response)
accuracy++;
}
// 精度(または信頼度)に応じてピクセルをハイライト表示します.
cvSet2D( img, i, j, response == 1 ?
(accuracy > 5 ? CV_RGB(180,0,0) : CV_RGB(180,120,0)) :
(accuracy > 5 ? CV_RGB(0,180,0) : CV_RGB(120,120,0)) );
}
}
// 元の学習サンプルを表示します.
for( i = 0; i < train_sample_count/2; i++ )
{
CvPoint pt;
pt.x = cvRound(trainData1.data.fl[i*2]);
pt.y = cvRound(trainData1.data.fl[i*2+1]);
cvCircle( img, pt, 2, CV_RGB(255,0,0), CV_FILLED );
pt.x = cvRound(trainData2.data.fl[i*2]);
pt.y = cvRound(trainData2.data.fl[i*2+1]);
cvCircle( img, pt, 2, CV_RGB(0,255,0), CV_FILLED );
}
cvNamedWindow( "classifier result", 1 );
cvShowImage( "classifier result", img );
cvWaitKey(0);
cvReleaseMat( &trainClasses );
cvReleaseMat( &trainData );
return 0;
}
ヘルプとフィードバック
お探しの情報が見つかりませんか?- チーシート(PDF) を読んでみてください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はOpenCV.jpまでお願いします.