特徴の検出と記述¶
cv::FAST¶
- void FAST(const Mat& image, vector<KeyPoint>& keypoints, int threshold, bool nonmaxSupression=true)¶
- Rosten (‘’Machine learning for high-speed corner detection’‘, 2006) によるFASTアルゴリズムを利用して,コーナーを検出します.
パラメタ: - image – 画像.ここからキーポイント(コーナー)が検出されます.
- keypoints – 画像から検出されたキーポイント.
- threshold – 中心ピクセルと,そのまわりの円周上のピクセルとの輝度値の差の閾値.アルゴリズムの説明を参照してください.
- nonmaxSupression – これが true の場合,検出されたコーナー(キーポイント)に対して non-maximum supression が適用されます.
MSER¶
- MSER¶
Maximally-Stable Extremal Region 抽出器.
class MSER : public CvMSERParams
{
public:
// デフォルトコンストラクタ
MSER();
// すべてのアルゴリズムパラメータを初期化するコンストラクタ
MSER( int _delta, int _min_area, int _max_area,
float _max_variation, float _min_diversity,
int _max_evolution, double _area_threshold,
double _min_margin, int _edge_blur_size );
// 指定した画像上でこの抽出器を走らせると,個々に輪郭
// ( vector<Point>, findContours を参照)としてエンコードされた複数の MSER が返されます.
// オプションマスクは, MSER を検索する対象となる領域を指定します.
void operator()( const Mat& image, vector<vector<Point> >& msers, const Mat& mask ) const;
};
このクラスは,MSER 抽出アルゴリズム( http://en.wikipedia.org/wiki/Maximally_stable_extremal_regions を参照してください)の全パラメータをカプセル化します.
StarDetector¶
- StarDetector¶
Star キーポイント検出器の実装.
class StarDetector : CvStarDetectorParams
{
public:
// デフォルトコンストラクタ
StarDetector();
// アルゴリズムの全パラメータを初期化するフルコンストラクタ:
// maxSize - 特徴の最大サイズ.
// 以下のパラメータ値がサポートされます:
// 4, 6, 8, 11, 12, 16, 22, 23, 32, 45, 46, 64, 90, 128
// responseThreshold - 近似されたラプラシアンに対する閾値.
// 弱い特徴を除外するために利用されます.これが大きくなるほど,
// 検出される特徴数が少なくなります.
// lineThresholdProjected - ラプラシアンに対する別の閾値.
// エッジを除外するために利用されます.
// lineThresholdBinarized - 特徴のサイズに対する別の閾値.
// エッジを除外するために利用されます.
// これら2つの閾値が大きくなるほど,検出される特徴点が増えます.
StarDetector(int maxSize, int responseThreshold,
int lineThresholdProjected,
int lineThresholdBinarized,
int suppressNonmaxSize);
// 画像中のキーポイントを検出します.
void operator()(const Mat& image, vector<KeyPoint>& keypoints) const;
};
このクラスは, Agrawal08 で述べられる CenSurE keypoint 検出器の改良版の実装です.
SIFT¶
- SIFT¶
キーポイントの検出および,Scale Invariant Feature Transform (SIFT) と呼ばれる手法を用いたディスクリプタを計算するクラス.
class CV_EXPORTS SIFT
{
public:
struct CommonParams
{
static const int DEFAULT_NOCTAVES = 4;
static const int DEFAULT_NOCTAVE_LAYERS = 3;
static const int DEFAULT_FIRST_OCTAVE = -1;
enum{ FIRST_ANGLE = 0, AVERAGE_ANGLE = 1 };
CommonParams();
CommonParams( int _nOctaves, int _nOctaveLayers, int _firstOctave,
int _angleMode );
int nOctaves, nOctaveLayers, firstOctave;
int angleMode;
};
struct DetectorParams
{
static double GET_DEFAULT_THRESHOLD()
{ return 0.04 / SIFT::CommonParams::DEFAULT_NOCTAVE_LAYERS / 2.0; }
static double GET_DEFAULT_EDGE_THRESHOLD() { return 10.0; }
DetectorParams();
DetectorParams( double _threshold, double _edgeThreshold );
double threshold, edgeThreshold;
};
struct DescriptorParams
{
static double GET_DEFAULT_MAGNIFICATION() { return 3.0; }
static const bool DEFAULT_IS_NORMALIZE = true;
static const int DESCRIPTOR_SIZE = 128;
DescriptorParams();
DescriptorParams( double _magnification, bool _isNormalize,
bool _recalculateAngles );
double magnification;
bool isNormalize;
bool recalculateAngles;
};
SIFT();
//! SIFT 検出器のコンストラクタ
SIFT( double _threshold, double _edgeThreshold,
int _nOctaves=CommonParams::DEFAULT_NOCTAVES,
int _nOctaveLayers=CommonParams::DEFAULT_NOCTAVE_LAYERS,
int _firstOctave=CommonParams::DEFAULT_FIRST_OCTAVE,
int _angleMode=CommonParams::FIRST_ANGLE );
//! SIFT 検出器のコンストラクタ
SIFT( double _magnification, bool _isNormalize=true,
bool _recalculateAngles = true,
int _nOctaves=CommonParams::DEFAULT_NOCTAVES,
int _nOctaveLayers=CommonParams::DEFAULT_NOCTAVE_LAYERS,
int _firstOctave=CommonParams::DEFAULT_FIRST_OCTAVE,
int _angleMode=CommonParams::FIRST_ANGLE );
SIFT( const CommonParams& _commParams,
const DetectorParams& _detectorParams = DetectorParams(),
const DescriptorParams& _descriptorParams = DescriptorParams() );
//! ディスクリプタのサイズを float (128) で返します.
int descriptorSize() const { return DescriptorParams::DESCRIPTOR_SIZE; }
//! SIFTアルゴリズムを用いてキーポイントを検出します.
void operator()(const Mat& img, const Mat& mask,
vector<KeyPoint>& keypoints) const;
//! SIFTアルゴリズムを用いてキーポイントを検出し,ディスクリプタを計算します.
//! オプションとして,ユーザが与えたキーポイントに対するディスクリプタを計算することもできます.
void operator()(const Mat& img, const Mat& mask,
vector<KeyPoint>& keypoints,
Mat& descriptors,
bool useProvidedKeypoints=false) const;
CommonParams getCommonParams () const { return commParams; }
DetectorParams getDetectorParams () const { return detectorParams; }
DescriptorParams getDescriptorParams () const { return descriptorParams; }
protected:
...
};
SURF¶
- SURF¶
画像から SURF 特徴を抽出するためのクラス.
class SURF : public CvSURFParams
{
public:
// デフォルトコンストラクタ
SURF();
// すべてのアルゴリズムパラメータを初期化するコンストラクタ
SURF(double _hessianThreshold, int _nOctaves=4,
int _nOctaveLayers=2, bool _extended=false);
// 各ディスクリプタの要素数( 64 または 128 )を返します.
int descriptorSize() const;
// 高速なマルチスケール Hesian 検出器を用いて keypoint を検出します.
void operator()(const Mat& img, const Mat& mask,
vector<KeyPoint>& keypoints) const;
// キーポイントを検出し,それらに対する SURF ディスクリプタを計算します.
// 出力ベクトル "descriptors" には,ディスクリプタの要素が格納され,
// そのサイズは descriptorSize()*keypoints.size() と等しくなります.
// 各ディスクリプタは descriptorSize() 個の要素を持ちます.
void operator()(const Mat& img, const Mat& mask,
vector<KeyPoint>& keypoints,
vector<float>& descriptors,
bool useProvidedKeypoints=false) const;
};
SURF クラスは,SURF ディスクリプタ Bay06 の実装です.(デフォルトでは)キーポイントの検出に,高速マルチスケール Hessian キーポイント検出器が利用されます. しかし,ディスクリプタ自体は,ユーザが指定した他のキーポイントに対しても計算することができます.この関数は,物体追跡,位置同定,画像スティッチングなどに利用できます. OpenCV のサンプルディレクトリにある find_obj.cpp デモを参照してください.
RandomizedTree¶
- RandomizedTree¶
RTreeClassifier に対する基本構造を含むクラス.
class CV_EXPORTS RandomizedTree
{
public:
friend class RTreeClassifier;
RandomizedTree();
~RandomizedTree();
void train(std::vector<BaseKeypoint> const& base_set,
cv::RNG &rng, int depth, int views,
size_t reduced_num_dim, int num_quant_bits);
void train(std::vector<BaseKeypoint> const& base_set,
cv::RNG &rng, PatchGenerator &make_patch, int depth,
int views, size_t reduced_num_dim, int num_quant_bits);
// 以下の 2 つの関数は実験的なものです.
// (何をやっているか正確に理解できなければ,利用しないでください)
static void quantizeVector(float *vec, int dim, int N, float bnds[2],
int clamp_mode=0);
static void quantizeVector(float *src, int dim, int N, float bnds[2],
uchar *dst);
// patch_datg は,必ず 32x32 の配列です(行のパディングはありません)
float* getPosterior(uchar* patch_data);
const float* getPosterior(uchar* patch_data) const;
uchar* getPosterior2(uchar* patch_data);
void read(const char* file_name, int num_quant_bits);
void read(std::istream &is, int num_quant_bits);
void write(const char* file_name) const;
void write(std::ostream &os) const;
int classes() { return classes_; }
int depth() { return depth_; }
void discardFloatPosteriors() { freePosteriors(1); }
inline void applyQuantization(int num_quant_bits)
{ makePosteriors2(num_quant_bits); }
private:
int classes_;
int depth_;
int num_leaves_;
std::vector<RTreeNode> nodes_;
float **posteriors_; // 16 バイトにアラインメント調整された事後確率
uchar **posteriors2_; // 16 バイトにアラインメント調整された事後確率
std::vector<int> leaf_counts_;
void createNodes(int num_nodes, cv::RNG &rng);
void allocPosteriorsAligned(int num_leaves, int num_classes);
void freePosteriors(int which);
// which: 1=posteriors_, 2=posteriors2_, 3=both
void init(int classes, int depth, cv::RNG &rng);
void addExample(int class_id, uchar* patch_data);
void finalize(size_t reduced_num_dim, int num_quant_bits);
int getIndex(uchar* patch_data) const;
inline float* getPosteriorByIndex(int index);
inline uchar* getPosteriorByIndex2(int index);
inline const float* getPosteriorByIndex(int index) const;
void convertPosteriorsToChar();
void makePosteriors2(int num_quant_bits);
void compressLeaves(size_t reduced_num_dim);
void estimateQuantPercForPosteriors(float perc[2]);
};
cv::RandomizedTree::train¶
- void train(std::vector<BaseKeypoint> const& base_set, cv::RNG &rng, PatchGenerator &make_patch, int depth, int views, size_t reduced_num_dim, int num_quant_bits)¶
入力キーポイント集合を用いて,ランダムツリーを学習します.
- void train(std::vector<BaseKeypoint> const& base_set, cv::RNG &rng, PatchGenerator &make_patch, int depth, int views, size_t reduced_num_dim, int num_quant_bits)
{ BaseKeypoint 型のベクトル.画像から得られたキーポイントが格納されており,これらが学習に利用されます.} {学習に利用される乱数生成器.} {学習に利用されるパッチ生成器.} {ツリーの深さの最大値.}
{圧縮されたシグネチャで利用される次元数.} {量子化に利用されるビット数.}
cv::RandomizedTree::read¶
- read(const char* file_name, int num_quant_bits)¶
事前に保存されたランダムツリーを,ファイルやストリームから読み込みます.
- read(std::istream &is, int num_quant_bits)
パラメタ: - file_name – ランダムツリーデータが保存されたファイルの名前.
- is – ランダムツリーデータが保存されたファイルに関連付けられた入力ストリーム.
{量子化に利用されるビット数.}
cv::RandomizedTree::write¶
- void write(const char* file_name) const¶
現在のランダムツリーを,ファイルやストリームに書き出します.
- void write(std::ostream &os) const
パラメタ: - file_name – ランダムツリーデータを保存するファイル名.
- is – ランダムツリーデータを保存するファイルに関連付けられた出力ストリーム.
cv::RandomizedTree::applyQuantization¶
- void applyQuantization(int num_quant_bits)¶
現在のランダムツリーを量子化します.
{量子化に利用されるビット数.}
RTreeNode¶
- RTreeNode¶
RandomizedTree に対する基本構造を含むクラス.
struct RTreeNode
{
short offset1, offset2;
RTreeNode() {}
RTreeNode(uchar x1, uchar y1, uchar x2, uchar y2)
: offset1(y1*PATCH_SIZE + x1),
offset2(y2*PATCH_SIZE + x2)
{}
//! 左の子は 0 ,右の子は 1 を返します.
inline bool operator() (uchar* patch_data) const
{
return patch_data[offset1] > patch_data[offset2];
}
};
RTreeClassifier¶
- RTreeClassifier¶
このクラスは, RTreeClassifier を含みます.それは, Michael Calonder によって提唱された calonder ディスクリプタを表現します.
class CV_EXPORTS RTreeClassifier
{
public:
static const int DEFAULT_TREES = 48;
static const size_t DEFAULT_NUM_QUANT_BITS = 4;
RTreeClassifier();
void train(std::vector<BaseKeypoint> const& base_set,
cv::RNG &rng,
int num_trees = RTreeClassifier::DEFAULT_TREES,
int depth = DEFAULT_DEPTH,
int views = DEFAULT_VIEWS,
size_t reduced_num_dim = DEFAULT_REDUCED_NUM_DIM,
int num_quant_bits = DEFAULT_NUM_QUANT_BITS,
bool print_status = true);
void train(std::vector<BaseKeypoint> const& base_set,
cv::RNG &rng,
PatchGenerator &make_patch,
int num_trees = RTreeClassifier::DEFAULT_TREES,
int depth = DEFAULT_DEPTH,
int views = DEFAULT_VIEWS,
size_t reduced_num_dim = DEFAULT_REDUCED_NUM_DIM,
int num_quant_bits = DEFAULT_NUM_QUANT_BITS,
bool print_status = true);
// sig は,少なくとも classes()*sizeof(float|uchar)
// バイトのメモリブロックを指さなければいけません.
void getSignature(IplImage *patch, uchar *sig);
void getSignature(IplImage *patch, float *sig);
void getSparseSignature(IplImage *patch, float *sig,
float thresh);
static int countNonZeroElements(float *vec, int n, double tol=1e-10);
static inline void safeSignatureAlloc(uchar **sig, int num_sig=1,
int sig_len=176);
static inline uchar* safeSignatureAlloc(int num_sig=1,
int sig_len=176);
inline int classes() { return classes_; }
inline int original_num_classes()
{ return original_num_classes_; }
void setQuantization(int num_quant_bits);
void discardFloatPosteriors();
void read(const char* file_name);
void read(std::istream &is);
void write(const char* file_name) const;
void write(std::ostream &os) const;
std::vector<RandomizedTree> trees_;
private:
int classes_;
int num_quant_bits_;
uchar **posteriors_;
ushort *ptemp_;
int original_num_classes_;
bool keep_floats_;
};
cv::RTreeClassifier::train¶
- void train(std::vector<BaseKeypoint> const& base_set, cv::RNG &rng, int num_trees = RTreeClassifier::DEFAULT_TREES, int depth = DEFAULT_DEPTH, int views = DEFAULT_VIEWS, size_t reduced_num_dim = DEFAULT_REDUCED_NUM_DIM, int num_quant_bits = DEFAULT_NUM_QUANT_BITS, bool print_status = true)
入力キーポイント集合を用いて,ランダムツリー分類器を学習します.
- void train(std::vector<BaseKeypoint> const& base_set, cv::RNG &rng, PatchGenerator &make_patch, int num_trees = RTreeClassifier::DEFAULT_TREES, int depth = DEFAULT_DEPTH, int views = DEFAULT_VIEWS, size_t reduced_num_dim = DEFAULT_REDUCED_NUM_DIM, int num_quant_bits = DEFAULT_NUM_QUANT_BITS, bool print_status = true)
{ BaseKeypoint 型のベクトル.ここに含まれる,画像から取得したキーポイントが学習に利用されます.} {学習に利用される乱数生成器.} {学習に利用されるパッチ生成器.} {RTreeClassificator 内のランダムツリーの数.} {ツリーの深さの最大値.}
{圧縮されたシグネチャで利用される次元数.} {量子化に利用されるビット数.} {現在の学習状況をコンソールに出力します.}
cv::RTreeClassifier::getSignature¶
- void getSignature(IplImage *patch, float *sig)
{画像パッチ.これに対するシグネチャが計算されます.} {出力されるシグネチャ(配列の次元は reduced_num_dim です).}
cv::RTreeClassifier::getSparseSignature¶
cv::RTreeClassifier::countNonZeroElements¶
- static int countNonZeroElements(float *vec, int n, double tol=1e-10)¶
この関数は,入力配列中の 0 ではない要素の個数を返します.
パラメタ: - vec – float 型の要素を含む入力ベクトル.
- n – 入力ベクトルのサイズ.
{要素のカウントに利用される閾値. tol より小さい値の要素をすべて 0 として扱います.}
cv::RTreeClassifier::read¶
- read(const char* file_name)
事前に保存された RTreeClassifier を,ファイルやストリームから読み込みます.
- read(std::istream &is)
パラメタ: - file_name – ランダムツリーデータが保存されたファイルの名前.
- is – ランダムツリーデータが保存されたファイルに関連付けられた入力ストリーム.
cv::RTreeClassifier::write¶
- void write(const char* file_name) const
現在の RTreeClassifier を,ファイルやストリームに書き出します.
- void write(std::ostream &os) const
パラメタ: - file_name – ランダムツリーデータを保存するファイル名.
- is – ランダムツリーデータを保存するファイルに関連付けられた出力ストリーム.
cv::RTreeClassifier::setQuantization¶
- void setQuantization(int num_quant_bits)¶
現在のランダムツリーを量子化します.
{量子化に利用されるビット数.}
以下に,
RTreeClassifier
を利用した特徴点マッチングの例を示します.ここでは,訓練画像とテスト画像があり,その両方から SURF 特徴を抽出します.そして,最も高い確率値と,それに対応する訓練画像の特徴インデックスが,
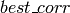 と
と
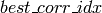 の配列に出力されます.
の配列に出力されます.
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq *objectKeypoints = 0, *objectDescriptors = 0;
CvSeq *imageKeypoints = 0, *imageDescriptors = 0;
CvSURFParams params = cvSURFParams(500, 1);
cvExtractSURF( test_image, 0, &imageKeypoints, &imageDescriptors,
storage, params );
cvExtractSURF( train_image, 0, &objectKeypoints, &objectDescriptors,
storage, params );
cv::RTreeClassifier detector;
int patch_width = cv::PATCH_SIZE;
iint patch_height = cv::PATCH_SIZE;
vector<cv::BaseKeypoint> base_set;
int i=0;
CvSURFPoint* point;
for (i=0;i<(n_points > 0 ? n_points : objectKeypoints->total);i++)
{
point=(CvSURFPoint*)cvGetSeqElem(objectKeypoints,i);
base_set.push_back(
cv::BaseKeypoint(point->pt.x,point->pt.y,train_image));
}
// 検出器の学習
cv::RNG rng( cvGetTickCount() );
cv::PatchGenerator gen(0,255,2,false,0.7,1.3,-CV_PI/3,CV_PI/3,
-CV_PI/3,CV_PI/3);
printf("RTree Classifier training...n");
detector.train(base_set,rng,gen,24,cv::DEFAULT_DEPTH,2000,
(int)base_set.size(), detector.DEFAULT_NUM_QUANT_BITS);
printf("Donen");
float* signature = new float[detector.original_num_classes()];
float* best_corr;
int* best_corr_idx;
if (imageKeypoints->total > 0)
{
best_corr = new float[imageKeypoints->total];
best_corr_idx = new int[imageKeypoints->total];
}
for(i=0; i < imageKeypoints->total; i++)
{
point=(CvSURFPoint*)cvGetSeqElem(imageKeypoints,i);
int part_idx = -1;
float prob = 0.0f;
CvRect roi = cvRect((int)(point->pt.x) - patch_width/2,
(int)(point->pt.y) - patch_height/2,
patch_width, patch_height);
cvSetImageROI(test_image, roi);
roi = cvGetImageROI(test_image);
if(roi.width != patch_width || roi.height != patch_height)
{
best_corr_idx[i] = part_idx;
best_corr[i] = prob;
}
else
{
cvSetImageROI(test_image, roi);
IplImage* roi_image =
cvCreateImage(cvSize(roi.width, roi.height),
test_image->depth, test_image->nChannels);
cvCopy(test_image,roi_image);
detector.getSignature(roi_image, signature);
for (int j = 0; j< detector.original_num_classes();j++)
{
if (prob < signature[j])
{
part_idx = j;
prob = signature[j];
}
}
best_corr_idx[i] = part_idx;
best_corr[i] = prob;
if (roi_image)
cvReleaseImage(&roi_image);
}
cvResetImageROI(test_image);
}
ヘルプとフィードバック
お探しの情報が見つかりませんか?- チーシート(PDF) を読んでみてください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はOpenCV.jpまでお願いします.
![]()
目次
- 特徴の検出と記述
- cv::FAST
- MSER
- StarDetector
- SIFT
- SURF
- RandomizedTree
- cv::RandomizedTree::train
- cv::RandomizedTree::read
- cv::RandomizedTree::write
- cv::RandomizedTree::applyQuantization
- RTreeNode
- RTreeClassifier
- cv::RTreeClassifier::train
- cv::RTreeClassifier::getSignature
- cv::RTreeClassifier::getSparseSignature
- cv::RTreeClassifier::countNonZeroElements
- cv::RTreeClassifier::read
- cv::RTreeClassifier::write
- cv::RTreeClassifier::setQuantization