XML/YAML Persistence¶
CvFileStorage¶
- CvFileStorage¶
File Storage.
typedef struct CvFileStorage
{
... // hidden fields
} CvFileStorage;
The structure CvFileStorage is a “black box” representation of the file storage associated with a file on disk. Several functions that are described below take CvFileStorage as inputs and allow theuser to save or to load hierarchical collections that consist of scalar values, standard CXCore objects (such as matrices, sequences, graphs), and user-defined objects.
CXCore can read and write data in XML (http://www.w3c.org/XML) or YAML
(http://www.yaml.org) formats. Below is an example of
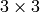 floating-point identity matrix
A
, stored in XML and YAML files
using CXCore functions:
floating-point identity matrix
A
, stored in XML and YAML files
using CXCore functions:
XML:
begin{verbatim} <?xml version=”1.0”> <opencv_storage> <A type_id=”opencv-matrix”>
<rows>3</rows> <cols>3</cols> <dt>f</dt> <data>1. 0. 0. 0. 1. 0. 0. 0. 1.</data>
</A> </opencv_storage>
end{verbatim} YAML:
begin{verbatim} A: !!opencv-matrix
rows: 3 cols: 3 dt: f data: [ 1., 0., 0., 0., 1., 0., 0., 0., 1.]
end{verbatim} As it can be seen from the examples, XML uses nested tags to represent hierarchy, while YAML uses indentation for that purpose (similar to the Python programming language).
The same CXCore functions can read and write data in both formats; the particular format is determined by the extension of the opened file, .xml for XML files and .yml or .yaml for YAML.
CvFileNode¶
- CvFileNode¶
File Storage Node.
/* file node type */
#define CV_NODE_NONE 0
#define CV_NODE_INT 1
#define CV_NODE_INTEGER CV_NODE_INT
#define CV_NODE_REAL 2
#define CV_NODE_FLOAT CV_NODE_REAL
#define CV_NODE_STR 3
#define CV_NODE_STRING CV_NODE_STR
#define CV_NODE_REF 4 /* not used */
#define CV_NODE_SEQ 5
#define CV_NODE_MAP 6
#define CV_NODE_TYPE_MASK 7
/* optional flags */
#define CV_NODE_USER 16
#define CV_NODE_EMPTY 32
#define CV_NODE_NAMED 64
#define CV_NODE_TYPE(tag) ((tag) & CV_NODE_TYPE_MASK)
#define CV_NODE_IS_INT(tag) (CV_NODE_TYPE(tag) == CV_NODE_INT)
#define CV_NODE_IS_REAL(tag) (CV_NODE_TYPE(tag) == CV_NODE_REAL)
#define CV_NODE_IS_STRING(tag) (CV_NODE_TYPE(tag) == CV_NODE_STRING)
#define CV_NODE_IS_SEQ(tag) (CV_NODE_TYPE(tag) == CV_NODE_SEQ)
#define CV_NODE_IS_MAP(tag) (CV_NODE_TYPE(tag) == CV_NODE_MAP)
#define CV_NODE_IS_COLLECTION(tag) (CV_NODE_TYPE(tag) >= CV_NODE_SEQ)
#define CV_NODE_IS_FLOW(tag) (((tag) & CV_NODE_FLOW) != 0)
#define CV_NODE_IS_EMPTY(tag) (((tag) & CV_NODE_EMPTY) != 0)
#define CV_NODE_IS_USER(tag) (((tag) & CV_NODE_USER) != 0)
#define CV_NODE_HAS_NAME(tag) (((tag) & CV_NODE_NAMED) != 0)
#define CV_NODE_SEQ_SIMPLE 256
#define CV_NODE_SEQ_IS_SIMPLE(seq) (((seq)->flags & CV_NODE_SEQ_SIMPLE) != 0)
typedef struct CvString
{
int len;
char* ptr;
}
CvString;
/* all the keys (names) of elements in the readed file storage
are stored in the hash to speed up the lookup operations */
typedef struct CvStringHashNode
{
unsigned hashval;
CvString str;
struct CvStringHashNode* next;
}
CvStringHashNode;
/* basic element of the file storage - scalar or collection */
typedef struct CvFileNode
{
int tag;
struct CvTypeInfo* info; /* type information
(only for user-defined object, for others it is 0) */
union
{
double f; /* scalar floating-point number */
int i; /* scalar integer number */
CvString str; /* text string */
CvSeq* seq; /* sequence (ordered collection of file nodes) */
struct CvMap* map; /* map (collection of named file nodes) */
} data;
}
CvFileNode;
The structure is used only for retrieving data from file storage (i.e., for loading data from the file). When data is written to a file, it is done sequentially, with minimal buffering. No data is stored in the file storage.
In opposite, when data is read from a file, the whole file is parsed and represented in memory as a tree. Every node of the tree is represented by CvFileNode . The type of file node N can be retrieved as CV_NODE_TYPE(N->tag) . Some file nodes (leaves) are scalars: text strings, integers, or floating-point numbers. Other file nodes are collections of file nodes, which can be scalars or collections in their turn. There are two types of collections: sequences and maps (we use YAML notation, however, the same is true for XML streams). Sequences (do not mix them with CvSeq ) are ordered collections of unnamed file nodes; maps are unordered collections of named file nodes. Thus, elements of sequences are accessed by index ( GetSeqElem ), while elements of maps are accessed by name ( GetFileNodeByName ). The table below describes the different types of file nodes:
| Type | CV_NODE_TYPE(node->tag) | Value |
|---|---|---|
| Integer | CV_NODE_INT | node->data.i |
| Floating-point | CV_NODE_REAL | node->data.f |
| Text string | CV_NODE_STR | node->data.str.ptr |
| Sequence | CV_NODE_SEQ | node->data.seq |
| Map | CV_NODE_MAP | node->data.map (see below) |
There is no need to access the map field directly (by the way, CvMap is a hidden structure). The elements of the map can be retrieved with the GetFileNodeByName function that takes a pointer to the “map” file node.
A user (custom) object is an instance of either one of the standard CxCore types, such as CvMat , CvSeq etc., or any type registered with RegisterTypeInfo . Such an object is initially represented in a file as a map (as shown in XML and YAML example files above) after the file storage has been opened and parsed. Then the object can be decoded (coverted to native representation) by request - when a user calls the Read or ReadByName functions.
CvAttrList¶
- CvAttrList¶
List of attributes.
typedef struct CvAttrList
{
const char** attr; /* NULL-terminated array of (attribute_name,attribute_value) pairs */
struct CvAttrList* next; /* pointer to next chunk of the attributes list */
}
CvAttrList;
/* initializes CvAttrList structure */
inline CvAttrList cvAttrList( const char** attr=NULL, CvAttrList* next=NULL );
/* returns attribute value or 0 (NULL) if there is no such attribute */
const char* cvAttrValue( const CvAttrList* attr, const char* attr_name );
In the current implementation, attributes are used to pass extra parameters when writing user objects (see Write ). XML attributes inside tags are not supported, aside from the object type specification ( type_id attribute).
CvTypeInfo¶
- CvTypeInfo¶
Type information.
typedef int (CV_CDECL *CvIsInstanceFunc)( const void* structPtr );
typedef void (CV_CDECL *CvReleaseFunc)( void** structDblPtr );
typedef void* (CV_CDECL *CvReadFunc)( CvFileStorage* storage, CvFileNode* node );
typedef void (CV_CDECL *CvWriteFunc)( CvFileStorage* storage,
const char* name,
const void* structPtr,
CvAttrList attributes );
typedef void* (CV_CDECL *CvCloneFunc)( const void* structPtr );
typedef struct CvTypeInfo
{
int flags; /* not used */
int header_size; /* sizeof(CvTypeInfo) */
struct CvTypeInfo* prev; /* previous registered type in the list */
struct CvTypeInfo* next; /* next registered type in the list */
const char* type_name; /* type name, written to file storage */
/* methods */
CvIsInstanceFunc is_instance; /* checks if the passed object belongs to the type */
CvReleaseFunc release; /* releases object (memory etc.) */
CvReadFunc read; /* reads object from file storage */
CvWriteFunc write; /* writes object to file storage */
CvCloneFunc clone; /* creates a copy of the object */
}
CvTypeInfo;
The structure CvTypeInfo contains information about one of the standard or user-defined types. Instances of the type may or may not contain a pointer to the corresponding CvTypeInfo structure. In any case, there is a way to find the type info structure for a given object using the TypeOf function. Aternatively, type info can be found by type name using FindType , which is used when an object is read from file storage. The user can register a new type with RegisterType that adds the type information structure into the beginning of the type list. Thus, it is possible to create specialized types from generic standard types and override the basic methods.
Clone¶
- void* cvClone(const void* structPtr)¶
Makes a clone of an object.
Parameters: - structPtr – The object to clone
The function finds the type of a given object and calls clone with the passed object.
EndWriteStruct¶
- void cvEndWriteStruct(CvFileStorage* fs)¶
Ends the writing of a structure.
Parameters: - fs – File storage
The function finishes the currently written structure.
FindType¶
- CvTypeInfo* cvFindType(const char* typeName)¶
Finds a type by its name.
Parameters: - typeName – Type name
The function finds a registered type by its name. It returns NULL if there is no type with the specified name.
FirstType¶
- CvTypeInfo* cvFirstType(void)¶
Returns the beginning of a type list.
The function returns the first type in the list of registered types. Navigation through the list can be done via the prev and next fields of the CvTypeInfo structure.
GetFileNode¶
- CvFileNode* cvGetFileNode(CvFileStorage* fs, CvFileNode* map, const CvStringHashNode* key, int createMissing=0)¶
Finds a node in a map or file storage.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches a top-level node. If both map and key are NULLs, the function returns the root file node - a map that contains top-level nodes.
- key – Unique pointer to the node name, retrieved with GetHashedKey
- createMissing – Flag that specifies whether an absent node should be added to the map
The function finds a file node. It is a faster version of GetFileNodeByName (see GetHashedKey discussion). Also, the function can insert a new node, if it is not in the map yet.
GetFileNodeByName¶
- CvFileNode* cvGetFileNodeByName(const CvFileStorage* fs, const CvFileNode* map, const char* name)¶
Finds a node in a map or file storage.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches in all the top-level nodes (streams), starting with the first one.
- name – The file node name
The function finds a file node by name . The node is searched either in map or, if the pointer is NULL, among the top-level file storage nodes. Using this function for maps and GetSeqElem (or sequence reader) for sequences, it is possible to nagivate through the file storage. To speed up multiple queries for a certain key (e.g., in the case of an array of structures) one may use a combination of GetHashedKey and GetFileNode .
GetFileNodeName¶
- const char* cvGetFileNodeName(const CvFileNode* node)¶
Returns the name of a file node.
Parameters: - node – File node
The function returns the name of a file node or NULL, if the file node does not have a name or if node is NULL .
GetHashedKey¶
- CvStringHashNode* cvGetHashedKey(CvFileStorage* fs, const char* name, int len=-1, int createMissing=0)¶
Returns a unique pointer for a given name.
Parameters: - fs – File storage
- name – Literal node name
- len – Length of the name (if it is known apriori), or -1 if it needs to be calculated
- createMissing – Flag that specifies, whether an absent key should be added into the hash table
The function returns a unique pointer for each particular file node name. This pointer can be then passed to the GetFileNode function that is faster than GetFileNodeByName because it compares text strings by comparing pointers rather than the strings’ content.
Consider the following example where an array of points is encoded as a sequence of 2-entry maps:
points:
- { x: 10, y: 10 }
- { x: 20, y: 20 }
- { x: 30, y: 30 }
# ...
Then, it is possible to get hashed “x” and “y” pointers to speed up decoding of the points.
#include "cxcore.h"
int main( int argc, char** argv )
{
CvFileStorage* fs = cvOpenFileStorage( "points.yml", 0, CV_STORAGE_READ );
CvStringHashNode* x_key = cvGetHashedNode( fs, "x", -1, 1 );
CvStringHashNode* y_key = cvGetHashedNode( fs, "y", -1, 1 );
CvFileNode* points = cvGetFileNodeByName( fs, 0, "points" );
if( CV_NODE_IS_SEQ(points->tag) )
{
CvSeq* seq = points->data.seq;
int i, total = seq->total;
CvSeqReader reader;
cvStartReadSeq( seq, &reader, 0 );
for( i = 0; i < total; i++ )
{
CvFileNode* pt = (CvFileNode*)reader.ptr;
#if 1 /* faster variant */
CvFileNode* xnode = cvGetFileNode( fs, pt, x_key, 0 );
CvFileNode* ynode = cvGetFileNode( fs, pt, y_key, 0 );
assert( xnode && CV_NODE_IS_INT(xnode->tag) &&
ynode && CV_NODE_IS_INT(ynode->tag));
int x = xnode->data.i; // or x = cvReadInt( xnode, 0 );
int y = ynode->data.i; // or y = cvReadInt( ynode, 0 );
#elif 1 /* slower variant; does not use x_key & y_key */
CvFileNode* xnode = cvGetFileNodeByName( fs, pt, "x" );
CvFileNode* ynode = cvGetFileNodeByName( fs, pt, "y" );
assert( xnode && CV_NODE_IS_INT(xnode->tag) &&
ynode && CV_NODE_IS_INT(ynode->tag));
int x = xnode->data.i; // or x = cvReadInt( xnode, 0 );
int y = ynode->data.i; // or y = cvReadInt( ynode, 0 );
#else /* the slowest yet the easiest to use variant */
int x = cvReadIntByName( fs, pt, "x", 0 /* default value */ );
int y = cvReadIntByName( fs, pt, "y", 0 /* default value */ );
#endif
CV_NEXT_SEQ_ELEM( seq->elem_size, reader );
printf("
}
}
cvReleaseFileStorage( &fs );
return 0;
}
Please note that whatever method of accessing a map you are using, it is still much slower than using plain sequences; for example, in the above example, it is more efficient to encode the points as pairs of integers in a single numeric sequence.
GetRootFileNode¶
- CvFileNode* cvGetRootFileNode(const CvFileStorage* fs, int stream_index=0)¶
Retrieves one of the top-level nodes of the file storage.
Parameters: - fs – File storage
- stream_index – Zero-based index of the stream. See StartNextStream . In most cases, there is only one stream in the file; however, there can be several.
The function returns one of the top-level file nodes. The top-level nodes do not have a name, they correspond to the streams that are stored one after another in the file storage. If the index is out of range, the function returns a NULL pointer, so all the top-level nodes may be iterated by subsequent calls to the function with stream_index=0,1,... , until the NULL pointer is returned. This function may be used as a base for recursive traversal of the file storage.
Load¶
- void* cvLoad(const char* filename, CvMemStorage* storage=NULL, const char* name=NULL, const char** realName=NULL)¶
Loads an object from a file.
Parameters: - filename – File name
- storage – Memory storage for dynamic structures, such as CvSeq or CvGraph . It is not used for matrices or images.
- name – Optional object name. If it is NULL, the first top-level object in the storage will be loaded.
- realName – Optional output parameter that will contain the name of the loaded object (useful if name=NULL )
The function loads an object from a file. It provides a simple interface to Read . After the object is loaded, the file storage is closed and all the temporary buffers are deleted. Thus, to load a dynamic structure, such as a sequence, contour, or graph, one should pass a valid memory storage destination to the function.
OpenFileStorage¶
- CvFileStorage* cvOpenFileStorage(const char* filename, CvMemStorage* memstorage, int flags)¶
Opens file storage for reading or writing data.
Parameters: - filename – Name of the file associated with the storage
- memstorage – Memory storage used for temporary data and for storing dynamic structures, such as CvSeq or CvGraph . If it is NULL, a temporary memory storage is created and used.
- flags –
Can be one of the following:
- CV_STORAGE_READ the storage is open for reading
- CV_STORAGE_WRITE the storage is open for writing
The function opens file storage for reading or writing data. In the latter case, a new file is created or an existing file is rewritten. The type of the read or written file is determined by the filename extension: .xml for XML and .yml or .yaml for YAML . The function returns a pointer to the CvFileStorage structure.
Read¶
- void* cvRead(CvFileStorage* fs, CvFileNode* node, CvAttrList* attributes=NULL)¶
Decodes an object and returns a pointer to it.
Parameters: - fs – File storage
- node – The root object node
- attributes – Unused parameter
The function decodes a user object (creates an object in a native representation from the file storage subtree) and returns it. The object to be decoded must be an instance of a registered type that supports the read method (see CvTypeInfo ). The type of the object is determined by the type name that is encoded in the file. If the object is a dynamic structure, it is created either in memory storage and passed to OpenFileStorage or, if a NULL pointer was passed, in temporary memory storage, which is released when ReleaseFileStorage is called. Otherwise, if the object is not a dynamic structure, it is created in a heap and should be released with a specialized function or by using the generic Release .
ReadByName¶
- void* cvReadByName(CvFileStorage* fs, const CvFileNode* map, const char* name, CvAttrList* attributes=NULL)¶
Finds an object by name and decodes it.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches a top-level node.
- name – The node name
- attributes – Unused parameter
The function is a simple superposition of GetFileNodeByName and Read .
ReadInt¶
- int cvReadInt(const CvFileNode* node, int defaultValue=0)¶
Retrieves an integer value from a file node.
Parameters: - node – File node
- defaultValue – The value that is returned if node is NULL
The function returns an integer that is represented by the file node. If the file node is NULL, the defaultValue is returned (thus, it is convenient to call the function right after GetFileNode without checking for a NULL pointer). If the file node has type CV_NODE_INT , then node->data.i is returned. If the file node has type CV_NODE_REAL , then node->data.f is converted to an integer and returned. Otherwise the result is not determined.
ReadIntByName¶
- int cvReadIntByName(const CvFileStorage* fs, const CvFileNode* map, const char* name, int defaultValue=0)¶
Finds a file node and returns its value.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches a top-level node.
- name – The node name
- defaultValue – The value that is returned if the file node is not found
The function is a simple superposition of GetFileNodeByName and ReadInt .
ReadRawData¶
- void cvReadRawData(const CvFileStorage* fs, const CvFileNode* src, void* dst, const char* dt)¶
Reads multiple numbers.
Parameters: - fs – File storage
- src – The file node (a sequence) to read numbers from
- dst – Pointer to the destination array
- dt – Specification of each array element. It has the same format as in WriteRawData .
The function reads elements from a file node that represents a sequence of scalars.
ReadRawDataSlice¶
- void cvReadRawDataSlice(const CvFileStorage* fs, CvSeqReader* reader, int count, void* dst, const char* dt)¶
Initializes file node sequence reader.
Parameters: - fs – File storage
- reader – The sequence reader. Initialize it with StartReadRawData .
- count – The number of elements to read
- dst – Pointer to the destination array
- dt – Specification of each array element. It has the same format as in WriteRawData .
The function reads one or more elements from
the file node, representing a sequence, to a user-specified array. The
total number of read sequence elements is a product of
total
and the number of components in each array element. For example, if
dt=
2if
, the function will read
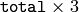 sequence elements. As with any sequence, some parts of the file node
sequence may be skipped or read repeatedly by repositioning the reader
using
SetSeqReaderPos
.
sequence elements. As with any sequence, some parts of the file node
sequence may be skipped or read repeatedly by repositioning the reader
using
SetSeqReaderPos
.
ReadReal¶
- double cvReadReal(const CvFileNode* node, double defaultValue=0.)¶
Retrieves a floating-point value from a file node.
Parameters: - node – File node
- defaultValue – The value that is returned if node is NULL
The function returns a floating-point value that is represented by the file node. If the file node is NULL, the defaultValue is returned (thus, it is convenient to call the function right after GetFileNode without checking for a NULL pointer). If the file node has type CV_NODE_REAL , then node->data.f is returned. If the file node has type CV_NODE_INT , then node-:math:`>`data.f is converted to floating-point and returned. Otherwise the result is not determined.
ReadRealByName¶
- double cvReadRealByName(const CvFileStorage* fs, const CvFileNode* map, const char* name, double defaultValue=0.)¶
Finds a file node and returns its value.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches a top-level node.
- name – The node name
- defaultValue – The value that is returned if the file node is not found
The function is a simple superposition of GetFileNodeByName and ReadReal .
ReadString¶
- const char* cvReadString(const CvFileNode* node, const char* defaultValue=NULL)¶
Retrieves a text string from a file node.
Parameters: - node – File node
- defaultValue – The value that is returned if node is NULL
The function returns a text string that is represented by the file node. If the file node is NULL, the defaultValue is returned (thus, it is convenient to call the function right after GetFileNode without checking for a NULL pointer). If the file node has type CV_NODE_STR , then node-:math:`>`data.str.ptr is returned. Otherwise the result is not determined.
ReadStringByName¶
- const char* cvReadStringByName(const CvFileStorage* fs, const CvFileNode* map, const char* name, const char* defaultValue=NULL)¶
Finds a file node by its name and returns its value.
Parameters: - fs – File storage
- map – The parent map. If it is NULL, the function searches a top-level node.
- name – The node name
- defaultValue – The value that is returned if the file node is not found
The function is a simple superposition of GetFileNodeByName and ReadString .
RegisterType¶
- void cvRegisterType(const CvTypeInfo* info)¶
Registers a new type.
Parameters: - info – Type info structure
The function registers a new type, which is described by info . The function creates a copy of the structure, so the user should delete it after calling the function.
Release¶
- void cvRelease(void** structPtr)¶
Releases an object.
Parameters: - structPtr – Double pointer to the object
The function finds the type of a given object and calls release with the double pointer.
ReleaseFileStorage¶
- void cvReleaseFileStorage(CvFileStorage** fs)¶
Releases file storage.
Parameters: - fs – Double pointer to the released file storage
The function closes the file associated with the storage and releases all the temporary structures. It must be called after all I/O operations with the storage are finished.
Save¶
- void cvSave(const char* filename, const void* structPtr, const char* name=NULL, const char* comment=NULL, CvAttrList attributes=cvAttrList())¶
Saves an object to a file.
Parameters: - filename – File name
- structPtr – Object to save
- name – Optional object name. If it is NULL, the name will be formed from filename .
- comment – Optional comment to put in the beginning of the file
- attributes – Optional attributes passed to Write
The function saves an object to a file. It provides a simple interface to Write .
StartNextStream¶
- void cvStartNextStream(CvFileStorage* fs)¶
Starts the next stream.
Parameters: - fs – File storage
The function starts the next stream in file storage. Both YAML and XML support multiple “streams.” This is useful for concatenating files or for resuming the writing process.
StartReadRawData¶
- void cvStartReadRawData(const CvFileStorage* fs, const CvFileNode* src, CvSeqReader* reader)¶
Initializes the file node sequence reader.
Parameters: - fs – File storage
- src – The file node (a sequence) to read numbers from
- reader – Pointer to the sequence reader
The function initializes the sequence reader to read data from a file node. The initialized reader can be then passed to ReadRawDataSlice .
StartWriteStruct¶
- void cvStartWriteStruct(CvFileStorage* fs, const char* name, int struct_flags, const char* typeName=NULL, CvAttrList attributes=cvAttrList( ))¶
Starts writing a new structure.
Parameters: - fs – File storage
- name – Name of the written structure. The structure can be accessed by this name when the storage is read.
- struct_flags –
A combination one of the following values:
- CV_NODE_SEQ the written structure is a sequence (see discussion of CvFileStorage ), that is, its elements do not have a name.
- CV_NODE_MAP the written structure is a map (see discussion of CvFileStorage ), that is, all its elements have names.
One and only one of the two above flags must be specified
- CV_NODE_FLOW – the optional flag that makes sense only for YAML streams. It means that the structure is written as a flow (not as a block), which is more compact. It is recommended to use this flag for structures or arrays whose elements are all scalars.
- typeName – Optional parameter - the object type name. In case of XML it is written as a type_id attribute of the structure opening tag. In the case of YAML it is written after a colon following the structure name (see the example in CvFileStorage description). Mainly it is used with user objects. When the storage is read, the encoded type name is used to determine the object type (see CvTypeInfo and FindTypeInfo ).
- attributes – This parameter is not used in the current implementation
The function starts writing a compound structure (collection) that can be a sequence or a map. After all the structure fields, which can be scalars or structures, are written, EndWriteStruct should be called. The function can be used to group some objects or to implement the write function for a some user object (see CvTypeInfo ).
TypeOf¶
- CvTypeInfo* cvTypeOf(const void* structPtr)¶
Returns the type of an object.
Parameters: - structPtr – The object pointer
The function finds the type of a given object. It iterates through the list of registered types and calls the is_instance function/method for every type info structure with that object until one of them returns non-zero or until the whole list has been traversed. In the latter case, the function returns NULL.
UnregisterType¶
- void cvUnregisterType(const char* typeName)¶
Unregisters the type.
Parameters: - typeName – Name of an unregistered type
The function unregisters a type with a specified name. If the name is unknown, it is possible to locate the type info by an instance of the type using TypeOf or by iterating the type list, starting from FirstType , and then calling cvUnregisterType(info->typeName) .
Write¶
- void cvWrite(CvFileStorage* fs, const char* name, const void* ptr, CvAttrList attributes=cvAttrList())¶
Writes a user object.
Parameters: - fs – File storage
- name – Name of the written object. Should be NULL if and only if the parent structure is a sequence.
- ptr – Pointer to the object
- attributes – The attributes of the object. They are specific for each particular type (see the dicsussion below).
The function writes an object to file storage. First, the appropriate type info is found using TypeOf . Then, the write method associated with the type info is called.
Attributes are used to customize the writing procedure. The standard types support the following attributes (all the *dt attributes have the same format as in WriteRawData ):
CvSeq
- header_dt description of user fields of the sequence header that follow CvSeq, or CvChain (if the sequence is a Freeman chain) or CvContour (if the sequence is a contour or point sequence)
- dt description of the sequence elements.
- recursive if the attribute is present and is not equal to “0” or “false”, the whole tree of sequences (contours) is stored.
Cvgraph
- header_dt description of user fields of the graph header that follows CvGraph;
- vertex_dt description of user fields of graph vertices
- edge_dt description of user fields of graph edges (note that the edge weight is always written, so there is no need to specify it explicitly)
Below is the code that creates the YAML file shown in the CvFileStorage description:
#include "cxcore.h"
int main( int argc, char** argv )
{
CvMat* mat = cvCreateMat( 3, 3, CV_32F );
CvFileStorage* fs = cvOpenFileStorage( "example.yml", 0, CV_STORAGE_WRITE );
cvSetIdentity( mat );
cvWrite( fs, "A", mat, cvAttrList(0,0) );
cvReleaseFileStorage( &fs );
cvReleaseMat( &mat );
return 0;
}
WriteComment¶
- void cvWriteComment(CvFileStorage* fs, const char* comment, int eolComment)¶
Writes a comment.
Parameters: - fs – File storage
- comment – The written comment, single-line or multi-line
- eolComment – If non-zero, the function tries to put the comment at the end of current line. If the flag is zero, if the comment is multi-line, or if it does not fit at the end of the current line, the comment starts a new line.
The function writes a comment into file storage. The comments are skipped when the storage is read, so they may be used only for debugging or descriptive purposes.
WriteFileNode¶
- void cvWriteFileNode(CvFileStorage* fs, const char* new_node_name, const CvFileNode* node, int embed)¶
Writes a file node to another file storage.
Parameters: - fs – Destination file storage
- new_file_node – New name of the file node in the destination file storage. To keep the existing name, use cvGetFileNodeName
- node – The written node
- embed – If the written node is a collection and this parameter is not zero, no extra level of hiararchy is created. Instead, all the elements of node are written into the currently written structure. Of course, map elements may be written only to a map, and sequence elements may be written only to a sequence.
The function writes a copy of a file node to file storage. Possible applications of the function are merging several file storages into one and conversion between XML and YAML formats.
WriteInt¶
- void cvWriteInt(CvFileStorage* fs, const char* name, int value)¶
Writes an integer value.
Parameters: - fs – File storage
- name – Name of the written value. Should be NULL if and only if the parent structure is a sequence.
- value – The written value
The function writes a single integer value (with or without a name) to the file storage.
WriteRawData¶
- void cvWriteRawData(CvFileStorage* fs, const void* src, int len, const char* dt)¶
Writes multiple numbers.
Parameters: - fs – File storage
- src – Pointer to the written array
- len – Number of the array elements to write
- dt –
Specification of each array element that has the following format ([count]{'u'|'c'|'w'|'s'|'i'|'f'|'d'})... where the characters correspond to fundamental C types:
- u 8-bit unsigned number
- c 8-bit signed number
- w 16-bit unsigned number
- s 16-bit signed number
- i 32-bit signed number
- f single precision floating-point number
- d double precision floating-point number
- r pointer, 32 lower bits of which are written as a signed integer. The type can be used to store structures with links between the elements. count is the optional counter of values of a given type. For
- example, 2if means that each array element is a structure of 2 integers, followed by a single-precision floating-point number. The equivalent notations of the above specification are ‘ iif ‘, ‘ 2i1f ‘ and so forth. Other examples: u means that the array consists of bytes, and 2d means the array consists of pairs of doubles.
The function writes an array, whose elements consist of single or multiple numbers. The function call can be replaced with a loop containing a few WriteInt and WriteReal calls, but a single call is more efficient. Note that because none of the elements have a name, they should be written to a sequence rather than a map.
WriteReal¶
- void cvWriteReal(CvFileStorage* fs, const char* name, double value)¶
Writes a floating-point value.
Parameters: - fs – File storage
- name – Name of the written value. Should be NULL if and only if the parent structure is a sequence.
- value – The written value
The function writes a single floating-point
value (with or without a name) to file storage. Special
values are encoded as follows: NaN (Not A Number) as .NaN,
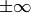 as +.Inf
(-.Inf).
as +.Inf
(-.Inf).
The following example shows how to use the low-level writing functions to store custom structures, such as termination criteria, without registering a new type.
void write_termcriteria( CvFileStorage* fs, const char* struct_name,
CvTermCriteria* termcrit )
{
cvStartWriteStruct( fs, struct_name, CV_NODE_MAP, NULL, cvAttrList(0,0));
cvWriteComment( fs, "termination criteria", 1 ); // just a description
if( termcrit->type & CV_TERMCRIT_ITER )
cvWriteInteger( fs, "max_iterations", termcrit->max_iter );
if( termcrit->type & CV_TERMCRIT_EPS )
cvWriteReal( fs, "accuracy", termcrit->epsilon );
cvEndWriteStruct( fs );
}
WriteString¶
- void cvWriteString(CvFileStorage* fs, const char* name, const char* str, int quote=0)¶
Writes a text string.
Parameters: - fs – File storage
- name – Name of the written string . Should be NULL if and only if the parent structure is a sequence.
- str – The written text string
- quote – If non-zero, the written string is put in quotes, regardless of whether they are required. Otherwise, if the flag is zero, quotes are used only when they are required (e.g. when the string starts with a digit or contains spaces).
The function writes a text string to file storage.
Help and Feedback
You did not find what you were looking for?- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.
![]()
Table Of Contents
- XML/YAML Persistence
- CvFileStorage
- CvFileNode
- CvAttrList
- CvTypeInfo
- Clone
- EndWriteStruct
- FindType
- FirstType
- GetFileNode
- GetFileNodeByName
- GetFileNodeName
- GetHashedKey
- GetRootFileNode
- Load
- OpenFileStorage
- Read
- ReadByName
- ReadInt
- ReadIntByName
- ReadRawData
- ReadRawDataSlice
- ReadReal
- ReadRealByName
- ReadString
- ReadStringByName
- RegisterType
- Release
- ReleaseFileStorage
- Save
- StartNextStream
- StartReadRawData
- StartWriteStruct
- TypeOf
- UnregisterType
- Write
- WriteComment
- WriteFileNode
- WriteInt
- WriteRawData
- WriteReal
- WriteString