物体検出¶
cv::MatchTemplate¶
- void cvMatchTemplate(const CvArr* image, const CvArr* templ, CvArr* result, int method)¶
テンプレートと,それと重なる領域の画像とを比較します.
パラメタ: - image – テンプレートとの比較を行う対象画像.8ビットあるいは32ビット,浮動小数点型
- templ – テンプレート.比較対象となる画像以下のサイズで,同じデータ型でなければならない
- result – 比較結果のマップ.シングルチャンネル,32ビット,浮動小数点型. image が
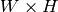 で, templ が
で, templ が 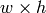 の場合, result は必ず
の場合, result は必ず 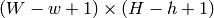 となります
となります - method – テンプレートと画像領域とを比較する方法(以下を参照してください)
この関数は,
CalcBackProjectPatch
と類似した関数です.画像
image
全体に対してテンプレート
templ
をずらしながら,それとサイズ
の重なり領域とを指定された方法で比較し,その結果を
result
に格納します.ここでは,それぞれの比較手法の式を示します(
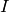 は
image
,
は
image
,
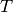 は
template
,
は
template
,
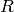 は
result
を表します).総和演算は,テンプレートと重なり領域の,どちらか片方あるいは両方に対して行われます:
は
result
を表します).総和演算は,テンプレートと重なり領域の,どちらか片方あるいは両方に対して行われます:
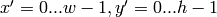
method=CV_TM_SQDIFF
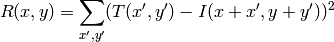
method=CV_TM_SQDIFF_NORMED
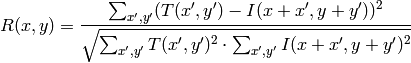
method=CV_TM_CCORR
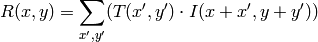
method=CV_TM_CCORR_NORMED
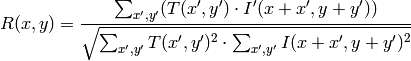
method=CV_TM_CCOEFF
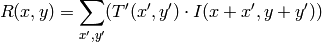
ここで,
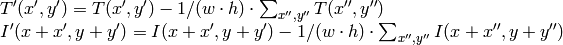
です.
method=CV_TM_CCOEFF_NORMED
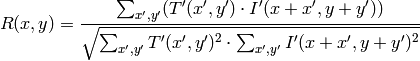
比較計算が終わると,関数 MinMaxLoc を用いて最も良いマッチング結果を,最小値( CV_TM_SQDIFF )や最大値( CV_TM_CCORR )として検出できます.カラー画像の場合,分母や分子のそれぞれの総和演算は,全てのチャンネルに対して行われます(それぞれチャンネルで,それぞれの平均値が用いられます).
物体検出のための Haar 特徴に基づくカスケード分類器¶
ここで述べられる物体検出器は, Paul Viola
Viola01
によって最初に提案され,Rainer Lienhart
Lienhart02
によって改良されたものです.まず,分類器(つまり,
haar-like特徴を用いるブースティングされた分類器のカスケード
)は,数百の正例と負例によって学習されます. 正例とは,同一のサイズ(例えば,
 )にスケーリングされた特定の物体(つまり,顔や車)を含むサンプル画像であり,負例とは,正例と同一サイズの任意の画像です.
)にスケーリングされた特定の物体(つまり,顔や車)を含むサンプル画像であり,負例とは,正例と同一サイズの任意の画像です.
学習が終わると,分類器は入力画像の(学習に用いられた物と同じサイズの)ROI に対して適用されます.その領域に物体(顔や車)が写っていると思われる場合は,分類器は「1」を出力し,それ以外では,「0」を出力します.画像全体から物体を探索するためには,画像中の探索窓を移動させながら,その個々の領域を分類器を用いて判別します.学習時とは異なるサイズの物体も検出できるように,分類器は簡単に「サイズ変更」できるように設計されており,これは画像自体のサイズを変更するよりも効率的です.そして,画像中からサイズ不明の物体を検出するためには,異なるスケールで複数回の探索処理が必要です.
分類器の名前にある「カスケード」という単語は,最終的に得られる分類器がいくつかの単純な分類器( stages )から構成される,という事を意味しています.この単純な分類器たちが ROI に対して次々に適用され,物体候補は,いずれかのステージで却下されるか,あるいは全てのステージを通過します.また,「ブーストされた」という単語は,カスケードの各ステージにおける単純な分類器自身が複合体である事を意味します.これらの単純な分類器は基本分類器から構成され,それには4種類の ブースティング 技法(重み付き投票)の内の1つが利用されます.現在のところ,Discrete Adaboost,Real Adaboost,Gentle Adaboost そして Logitboost がサポートされています.ここで利用される基本分類器は,少なくとも2つの葉を持つ決定木です. Haar-like 特徴はこの基本分類器の入力であり,その算出方法については後述します.現在のアルゴリズムでは次のような Haar-like 特徴を用いています:
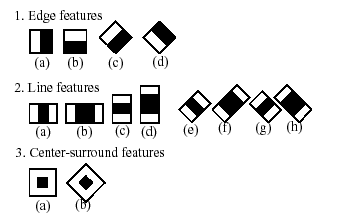
個々の分類器で用いられる特徴は,形状(1a, 2b など),ROI 内での位置,スケール(このスケールは検出ステージで用いられるスケールとは別物ですが,これら2つのスケールは乗じられます)によって規定されます.例えば,ライン特徴の3番目(2c)の場合,(2つの白ストライプと中央の黒ストライプを含む)特徴全体の矩形部分の画像ピクセルの和と,黒ストライプ部分の画像ピクセルの和を(領域サイズの違いを相殺するために)3倍したもの,との差分が出力となります.矩形領域全体のピクセル値の合計は,インテグラルイメージ(以下の説明,および Integral を参照してください)を用いて高速に計算されます.
物体検出器の動作を知りたい場合は,HaarFaceDetectデモを参照してください.
このリファレンスでは,検出部分についてのみ述べます.サンプル集合を用いて,ブーストされた分類器のカスケードを学習する haartraining と呼ばれる独立したアプリケーションが存在します.詳細は opencv/apps/haartraining を参照してください.
CvHaarFeature, CvHaarClassifier, CvHaarStageClassifier, CvHaarClassifierCascade¶
- CvHaarFeature, CvHaarClassifier, CvHaarStageClassifier, CvHaarClassifierCascade¶
ブーストされた Haar 分類器の構造体.
#define CV_HAAR_FEATURE_MAX 3
/* haar 特徴は適切な重みを持つ 2個,あるいは 3個の矩形から構成されます */
typedef struct CvHaarFeature
{
int tilted; /* 0 は,まっすぐな特徴,1 は,45度回転した特徴を意味します */
/* 2,3 個の矩形の重みは正負の符号を持ち,その絶対値は矩形の面積に反比例します.
rect[2].weight != 0 の場合,特徴は3個の矩形から構成され,
そうでない場合は2個の矩形から構成されます */
struct
{
CvRect r;
float weight;
} rect[CV_HAAR_FEATURE_MAX];
}
CvHaarFeature;
/* 単一決定木による基本分類器(最も単純な場合は stump).これは個々の画像位置
においての,特徴に対する応答(つまりウィンドウ内の部分矩形におけるピクセルの合計値)
を返し,それに依存する値を出力します */
typedef struct CvHaarClassifier
{
int count; /* 決定木のノード数 */
/* これらは「並列」な配列です.それぞれのインデックス ``i`` が,
決定木のノードに対応します(ルートノードのインデックスは0).
left[i] - 左側の子のインデックス
(左側の子が葉だった場合には負のインデックス)
right[i] - 右側の子のインデックス
(右側の子が葉だった場合には負のインデックス)
threshold[i] - 枝の閾値.特徴に対する応答が <= threshold となる場合は左側の枝が選択され,
そうでない場合は右の枝が選択されます.
alpha[i] - 葉に対応する出力値. */
CvHaarFeature* haar_feature;
float* threshold;
int* left;
int* right;
float* alpha;
}
CvHaarClassifier;
/* 基本分類器を組み合わせてブーストした分類器(=ステージ分類器):
基本分類器の応答の合計が ``threshold`` よりも
大きい場合は1を返し,そうでない場合は0を返します */
typedef struct CvHaarStageClassifier
{
int count; /* ステージ分類器に含まれる基本分類器の個数 */
float threshold; /* ステージ分類器で利用される閾値 */
CvHaarClassifier* classifier; /* 基本分類器の配列 */
/* これらのフィールドは,ステージ分類器を,
単純に一直線につながったカスケード構造だけでなく,
木構造で表現するために利用されます */
int next;
int child;
int parent;
}
CvHaarStageClassifier;
typedef struct CvHidHaarClassifierCascade CvHidHaarClassifierCascade;
/* ステージ分類器のカスケードまたは木構造 */
typedef struct CvHaarClassifierCascade
{
int flags; /* シグネチャ */
int count; /* ステージ数 */
CvSize orig_window_size; /* オリジナルの物体サイズ
(このカスケードは,これを学習対象とします) */
/* これら 2 つのパラメータは cvSetImagesForHaarClassifierCascade によって設定されます */
CvSize real_window_size; /* 現在の物体サイズ */
double scale; /* 現在のスケール */
CvHaarStageClassifier* stage_classifier; /* ステージ分類器の配列 */
CvHidHaarClassifierCascade* hid_cascade; /* cvSetImagesForHaarClassifierCascade
によって生成されるカスケードの,
隠れ最適表現 */
}
CvHaarClassifierCascade;
すべての構造体は,ブーストされたHaar分類器のカスケードを表現するために用いられます.このカスケードは次のような階層構造を持っています:
begin{verbatim} Cascade:
- Stage,,1,,:
- Classifier,,11,,:
- Feature,,11,,
- Classifier,,12,,:
- Feature,,12,,
...
- Stage,,2,,:
- Classifier,,21,,:
- Feature,,21,,
...
...
end{verbatim} 階層構造全体は,手動で構成されるか,あるいは関数 LoadHaarClassifierCascade を用いて,ファイルや内蔵のデータベースから読み込まれます.
cv::LoadHaarClassifierCascade¶
- CvHaarClassifierCascade* cvLoadHaarClassifierCascade(const char* directory, CvSize orig_window_size)¶
ファイル または OpenCV内に組み込まれた分類器データベースから,学習されたカスケード分類器を読み込みます.
パラメタ: - directory – 学習されたカスケード分類器のファイルを含むディレクトリ名
- orig_window_size – オリジナルの物体サイズ(カスケード分類器は,このサイズに合わせて学習されています).これはカスケード分類器内に保存されないので,別に指定する必要がある事に注意してください
この関数は,ファイル または OpenCV内に組み込まれた分類器データベースから,学習されたHaar分類器のカスケードを読み込みます.学習は,アプリケーション haartraining を用いて行うことができます(詳しくは,opencv/apps/haartraining を参照してください).
この関数は,廃止されます .現在では,物体検出分類器はディレクトリではなく XML/YAML ファイルに保存されます.ファイルからカスケードを読み込むためには,関数 Load を利用してください.
cv::HaarDetectObjects¶
..
- CvSeq* cvHaarDetectObjects(const CvArr* image, CvHaarClassifierCascade* cascade, CvMemStorage* storage, double scale_factor=1.1, int min_neighbors=3, int flags=0, CvSize min_size=cvSize(0, 0))¶
- 画像から物体検出を行います.
typedef struct CvAvgComp {
CvRect rect; /* オブジェクトを内包する矩形(グループの平均矩形) / int neighbors; / グループ内に存在する隣接矩形の数 */
} CvAvgComp;
param image: この画像の中から物体を検出する param cascade: Haar分類器カスケードの内部表現 param storage: 物体候補の矩形列を保存するメモリストレージ param scale_factor: スキャン毎にスケーリングされる探索窓のスケーリングファクタ.たとえば,これが1.1ならば,探索窓が10 % 大きくなります %–
param scale_factor: The factor by which the search window is scaled between the subsequent scans, 1.1 means increasing window by 10 % param min_neighbors: (これから1を引いた値が)物体を表す矩形を構成する近傍矩形の最小数. min_neighbors -1 より少ない数の矩形しか含まないグループは,全て棄却されます. min_neighbors が0 の場合は,グループ化が行われずに,物体の候補となる個々の矩形が全て返されます.これは,ユーザが独自のグループ化処理を行いたい場合に有用です param flags: 処理モード.現在は, CV_HAAR_DO_CANNY_PRUNING のみ有効です.このフラグが指定されている場合,関数はCannyエッジ検出器を利用し,非常に多くのエッジを含む(あるいは非常に少ないエッジしか含まない)画像領域を,探索物体を含まない領域であると見なして棄却します.特定の閾値は顔検出用に調整されており,この場合,枝刈りにより処理が高速化されます param min_size: 探索窓の最小サイズ.デフォルトでは,分類器の学習に用いられたサンプルのサイズが設定されます(顔検出の場合は )
この関数は,与えられた画像から,カスケードの学習対象となった物体を含むであろう矩形領域を検出し,それらの領域を矩形のシーケンスとして返します.これは,画像のスキャンを異なるスケールで複数回行います(
SetImagesForHaarClassifierCascade
を参照してください).毎回,各スケールにあった画像領域を処理対象とし,
RunHaarClassifierCascade
を用いて,分類器をこの領域に適用します.また,判別する領域数を減らすために,Cannyエッジ検出器を用いた枝刈り処理のようなヒューリスティックな手法を適用することもあります.処理された物体候補矩形(分類器カスケードに渡された領域)が集められると,それらはグループ化され,さらに十分に大きいグループの平均矩形のみがシーケンスとして返されます.デフォルトパラメータ(
scale_factor
=1.1,
min_neighbors
=3,
flags
=0)は,正確ではあるが低速な物体検出用に調整されたものです.実際の動画像に対する,より高速な処理のためには,以下のような値が考えられます:
scale_factor
=1.2,
min_neighbors
=2,
flags
=
CV_HAAR_DO_CANNY_PRUNING
,
min_size
=
あり得る最小の顔サイズ
(例えばビデオ会議の場合は,画面全体の
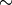 1/4 から 1/16 )
1/4 から 1/16 )
#include "cv.h"
#include "highgui.h"
CvHaarClassifierCascade* load_object_detector( const char* cascade_path )
{
return (CvHaarClassifierCascade*)cvLoad( cascade_path );
}
void detect_and_draw_objects( IplImage* image,
CvHaarClassifierCascade* cascade,
int do_pyramids )
{
IplImage* small_image = image;
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* faces;
int i, scale = 1;
/* このフラグが指定された場合,(おそらく)クオリティを落とさずに
ブースティングのパフォーマンスを上げるために,入力画像をダウンスケールします */
if( do_pyramids )
{
small_image = cvCreateImage( cvSize(image->width/2,image->height/2), IPL_DEPTH_8U, 3 );
cvPyrDown( image, small_image, CV_GAUSSIAN_5x5 );
scale = 2;
}
/* 高速に検出できるように引数を調整します */
faces = cvHaarDetectObjects( small_image, cascade, storage, 1.2, 2, CV_HAAR_DO_CANNY_PRUNING );
/* すべての矩形を描画します */
for( i = 0; i < faces->total; i++ )
{
/* 矩形だけを取り出します */
CvRect face_rect = *(CvRect*)cvGetSeqElem( faces, i );
cvRectangle( image, cvPoint(face_rect.x*scale,face_rect.y*scale),
cvPoint((face_rect.x+face_rect.width)*scale,
(face_rect.y+face_rect.height)*scale),
CV_RGB(255,0,0), 3 );
}
if( small_image != image )
cvReleaseImage( &small_image );
cvReleaseMemStorage( &storage );
}
/* 画像ファイル名とカスケードのパスをコマンドラインから受け取ります */
int main( int argc, char** argv )
{
IplImage* image;
if( argc==3 && (image = cvLoadImage( argv[1], 1 )) != 0 )
{
CvHaarClassifierCascade* cascade = load_object_detector(argv[2]);
detect_and_draw_objects( image, cascade, 1 );
cvNamedWindow( "test", 0 );
cvShowImage( "test", image );
cvWaitKey(0);
cvReleaseHaarClassifierCascade( &cascade );
cvReleaseImage( &image );
}
return 0;
}
cv::SetImagesForHaarClassifierCascade¶
- void cvSetImagesForHaarClassifierCascade(CvHaarClassifierCascade* cascade, const CvArr* sum, const CvArr* sqsum, const CvArr* tilted_sum, double scale)¶
カスケードの隠れ表現に,インテグラルイメージを割り当てます.
パラメタ: - cascade – CreateHidHaarClassifierCascade によって作成される,隠れHaar分類器のカスケード
- sum – インテグラルイメージ.シングルチャンネル,32ビット整数型フォーマット.後の2つの画像と同様に,特徴の高速な評価と明るさ/コントラストの正規化に利用されます.これらの画像は,関数 Integral を用いて,8ビットあるいは浮動小数点型のシングルチャンネル画像から作成できます
- sqsum – 2乗和インテグラルイメージ.64ビット浮動小数点型フォーマット
- tilted_sum – 傾いたインテグラルイメージ.シングルチャンネル,32ビット整数型フォーマット
- scale – カスケードの探索窓サイズ. scale =1 ならば,オリジナルの探索窓サイズが用いられます(そのサイズの物体が探索されます).そのサイズは, LoadHaarClassifierCascade で指定されたものと同じです( default_face_cascade の場合は
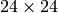 ). scale =2 ならば,2倍サイズの探索窓が利用されます(デフォルトの顔検出カスケードの場合は,
). scale =2 ならば,2倍サイズの探索窓が利用されます(デフォルトの顔検出カスケードの場合は, 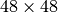 ).この場合,探索は約4倍高速になりますが, より小さい顔を検出できなくなります
).この場合,探索は約4倍高速になりますが, より小さい顔を検出できなくなります
この関数は,画像と探索窓スケールのどちらか,あるいは両方を分類器のカスケードの隠れ表現に割り当てます.画像のポインタがNULLである場合,前回セットされた画像が再び用いられます(つまり,NULLは「画像を変更しない」という意味です).スケールパラメータにはこのようなデフォルト値がありませんが,関数 GetHaarClassifierCascadeScale によって前回の値を取得し,それを再利用することは可能です.この関数は,特定の画像から特定サイズの物体を検出するカスケードを準備するために利用されます.また,この関数は HaarDetectObjects によって内部的に呼び出されますが,低レベルな関数 RunHaarClassifierCascade を利用する場合は,ユーザが呼び出すこともできます.
cv::ReleaseHaarClassifierCascade¶
- void cvReleaseHaarClassifierCascade(CvHaarClassifierCascade** cascade)¶
Haar分類器カスケードを解放します.
Parameter: cascade – 解放するカスケード分類器へのダブルポインタ.ポインタは,この関数によってクリアされます
この関数は,手動で作成された,あるいは LoadHaarClassifierCascade や Load によって読み込まれたカスケード分類器を解放します.
cv::RunHaarClassifierCascade¶
- int cvRunHaarClassifierCascade(CvHaarClassifierCascade* cascade, CvPoint pt, int start_stage=0)¶
与えられた画像位置において,ブーストされた分類器のカスケードを実行します.
パラメタ: - cascade – Haar分類器のカスケード
- pt – 判別対象となる領域の左上の座標.この領域のサイズは,オリジナルの探索窓サイズを現在のスケールファクタでスケーリングしたものです.現在の探索窓サイズは,関数 GetHaarClassifierCascadeWindowSize を利用して取得できます
- start_stage – 0から始まるインデックスで,カスケードの開始ステージを決定します.この関数は,開始ステージ以前の全ステージを通過したことを仮定します.この機能は,CPUのキャッシュを効率的に利用するために HaarDetectObjects によって内部的に利用される
この関数は,ブーストされた分類器のカスケードをある特定の画像位置で動作させます.この関数を使う前に, SetImagesForHaarClassifierCascade を用いて,インテグラルイメージと適切なスケール(探索窓サイズ)をセットしなければいけません.この関数は,判別対象領域が全ての分類器ステージを通過した(つまり,物体候補となった)場合は正の値を返し,そうでない場合は0か負の値を返します.
ヘルプとフィードバック
お探しの情報が見つかりませんか?- FAQ (英語)を試してください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はopencv.jpまでお願い します.