ブースティング¶
一般的な機械学習のタスクは,教師あり学習です.教師あり学習では,入力
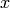 と出力
と出力
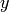 の間の関数関係
の間の関数関係
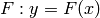 を学習することが目的です.定性的な値の予測は分類と呼ばれ,定量的な値の予測は回帰と呼ばれます.
を学習することが目的です.定性的な値の予測は分類と呼ばれ,定量的な値の予測は回帰と呼ばれます.
ブースティングは教師あり分類の学習タスクを解決する強力な学習概念です.これは,たくさんの「弱い」分類器の能力を組み合わせることで,強力な「コミッティ」 HTF01 を構成します.弱い分類器は,偶然よりもマシな性能を持っていれば良いため,非常にシンプルで計算コストの小さいものとなります.しかし,多数の弱い分類器を上手く組み合わせることで,強力な分類器が構成できます.これは,SVM やニューラルネットワークなどの「単一の」強力な分類器よりも良い性能を示すことも多くあります.
決定木は,ブースティングの枠組みに用いられる最も有名な弱い分類器です.多くの場合,1つの木に1つの分岐ノードしかない,(stump と呼ばれる)最も単純な決定木で十分です.
ブーストモデルは,
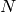 個の学習サンプル
個の学習サンプル
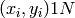 (ここで
(ここで
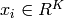 ,
,
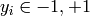 )に基づいています.
)に基づいています.
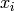 は
は
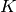 要素のベクトルです.それぞれの要素は,現在の学習タスクに関連する特徴をエンコードしたものです.また,目的とする2つのクラスは,-1 と +1 にエンコードされます.
要素のベクトルです.それぞれの要素は,現在の学習タスクに関連する特徴をエンコードしたものです.また,目的とする2つのクラスは,-1 と +1 にエンコードされます.
ブースティングの様々な変化形として, Discrete Adaboost, Real AdaBoost, LogitBoost, そして Gentle AdaBoost
FHT98
などが知られています.これらはすべて,全体的な構造が非常に似ているので,以下では標準的な2クラスの Discrete AdaBoost についてのみ考察します.初期状態では,各サンプルに対して同一の重みが与えられます(ステップ2).次に,重みづけられた学習データを用いて,弱い分類器
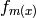 を学習します(ステップ3a).また,この重み付き学習の誤差とスケーリングファクタ
を学習します(ステップ3a).また,この重み付き学習の誤差とスケーリングファクタ
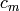 が求められます(ステップ3b).そして,分類に失敗したサンプルに対する重みが増加されます(ステップ3c).すべての重みが正規化された後,次の弱い分類器を計算する処理がさらに
が求められます(ステップ3b).そして,分類に失敗したサンプルに対する重みが増加されます(ステップ3c).すべての重みが正規化された後,次の弱い分類器を計算する処理がさらに
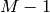 回繰り返されます.最終的な分類器
回繰り返されます.最終的な分類器
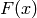 は,個々の弱い分類器の重み付き和の符号を出力します(ステップ4).
は,個々の弱い分類器の重み付き和の符号を出力します(ステップ4).
-
個のサンプル
(ここで
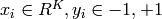 )が与えられます.
)が与えられます. - 重みは
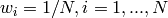 の状態から開始されます.
の状態から開始されます. 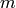 =
=
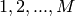 に対して,以下の処理を繰り返します:
に対して,以下の処理を繰り返します:- 学習データに対する重み
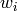 を用いて,分類器
を用いて,分類器
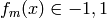 を学習します.
を学習します. ![err_m = E_w [1_{(y =\neq f_m(x))}], c_m = log((1 - err_m)/err_m)](_images/math/53d0505d2c31cea8f8e1e7e9696a2901d8fbdaa7.png) を計算します.
を計算します.![w_i \Leftarrow w_i exp[c_m 1_{(y_i \neq f_m(x_i))}], i = 1,2,...,N,](_images/math/802c59f9558fed254c3e34a9c7aa3cf0d8b9318b.png) というように重みをセットし,
というように重みをセットし,
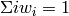 となるように正規化します.
となるように正規化します.![[\Sigma m = 1M c_m f_m(x)]](_images/math/5ae9480b5b5252d3d1115f4a536a5f806f309501.png) の符号を出力します.
の符号を出力します.
- 学習データに対する重み
2クラス Discrete AdaBoost アルゴリズム:学習(ステップ1 から 3)と評価(ステップ4)
注意:
古典的ブースティング手法と同様に,現在の実装でも2クラス分類器だけがサポートされています. M
 2 クラスに対しては,
FHT98
で述べられる
AdaBoost.MH
アルゴリズムが存在します.これは大量の学習データを必要としますが,問題を2クラス問題に帰着させます.
2 クラスに対しては,
FHT98
で述べられる
AdaBoost.MH
アルゴリズムが存在します.これは大量の学習データを必要としますが,問題を2クラス問題に帰着させます.
精度を大きく損なうことなくブーストモデルの計算時間を減らすために,影響力を考慮したトリミング(influence trimming technique)を利用する場合があります.学習時にアンサンブル内の木の個数が増加すると,より多くの学習サンプルが正しく分類され,信頼性が増加します.その結果,それらのサンプルは以降の繰り返し計算では小さい重みが付けられます.相対的な重みが非常に小さいサンプルは,弱い学習器の学習においてほとんど影響を与えません.よって,このようなサンプルを弱い学習器の学習中に排除しても,最終的に生成される分類器にあまり影響しないと考えられます.この処理は,weight _ trim _ rate パラメータにより制御されます.全体の重みの上位 weight _ trim _ rate の割合を占める重みをもつサンプルだけが,弱い分類器の学習に利用されます. すべて の学習サンプルに対する重みが,学習の反復毎に再計算されることに注意してください.ある反復において削除されたサンプルも,別の弱い学習器を学習する際には再利用される可能性があります FHT98 .
[HTF01] Hastie, T., Tibshirani, R., Friedman, J. H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer Series in Statistics. 2001. [FHT98] Friedman, J. H., Hastie, T. and Tibshirani, R. Additive Logistic Regression: a Statistical View of Boosting. Technical Report, Dept. of Statistics, Stanford University, 1998.
CvBoostParams¶
- CvBoostParams¶
ブースティング学習パラメータ.
struct CvBoostParams : public CvDTreeParams
{
int boost_type;
int weak_count;
int split_criteria;
double weight_trim_rate;
CvBoostParams();
CvBoostParams( int boost_type, int weak_count, double weight_trim_rate,
int max_depth, bool use_surrogates, const float* priors );
};
この構造体は CvDTreeParams からの派生ですが,決定木パラメータをすべてサポートしているわけではありません.具体的には,交差検証法がサポートされていません.
CvBoostTree¶
- CvBoostTree¶
弱い木分類器.
class CvBoostTree: public CvDTree
{
public:
CvBoostTree();
virtual ~CvBoostTree();
virtual bool train( CvDTreeTrainData* _train_data,
const CvMat* subsample_idx, CvBoost* ensemble );
virtual void scale( double s );
virtual void read( CvFileStorage* fs, CvFileNode* node,
CvBoost* ensemble, CvDTreeTrainData* _data );
virtual void clear();
protected:
...
CvBoost* ensemble;
};
ブーストされた木分類器 CvBoost の要素である弱い分類器は, CvDTree から派生したものです.通常,ユーザが弱い分類器を直接使う必要はありませんが,シーケンス CvBoost::weak の要素としてアクセスしたり, CvBoost::get_weak_predictors メソッドによって取得したりすることも可能です.
LogitBoost と Gentle AdaBoost の場合,それぞれの弱い分類器は分類木ではなく回帰木であることに注意してください.また,Discrete AdaBoost と Real AdaBoost の場合でも, CvBoostTree::predict の戻り値( CvDTreeNode::value )は,出力クラスラベルではありません.クラス # 0 に対しては負の値が,クラス # 1 に対しては正の値が,それぞれ「投票」されます.そして,この投票に対して重み付けがなされます.個々の弱い分類器の重みは, CvBoostTree::scale メソッドによって増減されます.
CvBoost¶
- CvBoost¶
ブーストされた木分類器.
class CvBoost : public CvStatModel
{
public:
// ブースティングの種類
enum { DISCRETE=0, REAL=1, LOGIT=2, GENTLE=3 };
// 分岐基準
enum { DEFAULT=0, GINI=1, MISCLASS=3, SQERR=4 };
CvBoost();
virtual ~CvBoost();
CvBoost( const CvMat* _train_data, int _tflag,
const CvMat* _responses, const CvMat* _var_idx=0,
const CvMat* _sample_idx=0, const CvMat* _var_type=0,
const CvMat* _missing_mask=0,
CvBoostParams params=CvBoostParams() );
virtual bool train( const CvMat* _train_data, int _tflag,
const CvMat* _responses, const CvMat* _var_idx=0,
const CvMat* _sample_idx=0, const CvMat* _var_type=0,
const CvMat* _missing_mask=0,
CvBoostParams params=CvBoostParams(),
bool update=false );
virtual float predict( const CvMat* _sample, const CvMat* _missing=0,
CvMat* weak_responses=0, CvSlice slice=CV_WHOLE_SEQ,
bool raw_mode=false ) const;
virtual void prune( CvSlice slice );
virtual void clear();
virtual void write( CvFileStorage* storage, const char* name );
virtual void read( CvFileStorage* storage, CvFileNode* node );
CvSeq* get_weak_predictors();
const CvBoostParams& get_params() const;
...
protected:
virtual bool set_params( const CvBoostParams& _params );
virtual void update_weights( CvBoostTree* tree );
virtual void trim_weights();
virtual void write_params( CvFileStorage* fs );
virtual void read_params( CvFileStorage* fs, CvFileNode* node );
CvDTreeTrainData* data;
CvBoostParams params;
CvSeq* weak;
...
};
CvBoost::train¶
- bool CvBoost::train(const CvMat* _train_data, int _tflag, const CvMat* _responses, const CvMat* _var_idx=0, const CvMat* _sample_idx=0, const CvMat* _var_type=0, const CvMat* _missing_mask=0, CvBoostParams params=CvBoostParams(), bool update=false)¶
ブーストされた木分類器を学習します.
この train メソッドは,共通の形式に従います.最後のパラメータ update は,分類器を更新する必要があるか(つまり,新しい弱い分類器が既に存在するアンサンブルに追加されます),あるいは分類器を一から作り直す必要があるか,を指定します.これの応答は,2クラスのカテゴリ変数でなければいけません.つまり,ブーストされた木分類器は,回帰には利用できません.
CvBoost::predict¶
- float CvBoost::predict(const CvMat* sample, const CvMat* missing=0, CvMat* weak_responses=0, CvSlice slice=CV_WHOLE_SEQ, bool raw_mode=false) const¶
入力サンプルに対する応答を予測します.
CvBoost::predict メソッドは,アンサンブル内の決定木それぞれにサンプルを入力し,その重み付き投票に基づいた出力クラスラベルを返します.
CvBoost::prune¶
- void CvBoost::prune(CvSlice slice)¶
指定された弱い分類器を削除します.
このメソッドは,指定された弱い分類器をシーケンスから削除します.このメソッドを,個々の決定木の枝刈り(現在はサポートされていません)と混同しないように注意してください.
ヘルプとフィードバック
お探しの情報が見つかりませんか?- チーシート(PDF) を読んでみてください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はOpenCV.jpまでお願いします.