物体検出¶
FeatureEvaluator¶
- FeatureEvaluator¶
カスケード分類器で特徴量を求めるための基底クラス.
class CV_EXPORTS FeatureEvaluator
{
public:
enum { HAAR = 0, LBP = 1 }; // サポートされる特徴タイプ
virtual ~FeatureEvaluator(); // デストラクタ
virtual bool read(const FileNode& node);
virtual Ptr<FeatureEvaluator> clone() const;
virtual int getFeatureType() const;
virtual bool setImage(const Mat& img, Size origWinSize);
virtual bool setWindow(Point p);
virtual double calcOrd(int featureIdx) const;
virtual int calcCat(int featureIdx) const;
static Ptr<FeatureEvaluator> create(int type);
};
cv::FeatureEvaluator::read¶
cv::FeatureEvaluator::clone¶
- Ptr<FeatureEvaluator> FeatureEvaluator::clone() const¶
- 特徴量評価器の完全なコピーを返します.
cv::FeatureEvaluator::getFeatureType¶
- int FeatureEvaluator::getFeatureType() const¶
- 特徴量タイプ(現在は HAAR か LBP)を返します.
cv::FeatureEvaluator::setImage¶
cv::FeatureEvaluator::setWindow¶
- bool FeatureEvaluator::setWindow(Point p)¶
現在の画像上に,特徴量を計算する探索窓をセットします( によって呼び出されます)
Parameter: p – 探索窓の左上角の座標.この探索窓の中の特徴量が計算されます.探索窓のサイズは,学習画像と同じです
cv::FeatureEvaluator::calcOrd¶
- double FeatureEvaluator::calcOrd(int featureIdx) const¶
順序付き(数値)特徴量の値を求めます.
Parameter: featureIdx – 値を求める特徴量のインデックス
求められた順序付き特徴量の値を返します.
cv::FeatureEvaluator::calcCat¶
- int FeatureEvaluator::calcCat(int featureIdx) const¶
カテゴリ特徴量の値を求めます.
Parameter: featureIdx – 値を求める特徴量のインデックス
求められたカテゴリ特徴量,つまり [0,... (カテゴリ数 - 1)] の範囲内の値を返します.
cv::FeatureEvaluator::create¶
- static Ptr<FeatureEvaluator> FeatureEvaluator::create(int type)¶
特徴量評価器を作成します.
Parameter: type – カスケードによって評価される特徴量の種類(現在は,HAAR または LBP のどちらか)
CascadeClassifier¶
- CascadeClassifier¶
物体検出のためのカスケード分類器クラス.
class CascadeClassifier
{
public:
// 木ノードを表す構造体
struct CV_EXPORTS DTreeNode
{
int featureIdx; // 分岐となる特徴量インデックス
float threshold; // 順序付き特徴量に対する分岐の閾値
int left; // 木ノード配列において,左側にある子ノードのインデックス
int right; // 木ノード配列において,右側にある子ノードのインデックス
};
// 決定木を表す構造体
struct CV_EXPORTS DTree
{
int nodeCount; // ノード数
};
// カスケードステージ(現在のところ BOOST のみ)を表す構造体
struct CV_EXPORTS Stage
{
int first; // 木配列における,最初の木のインデックス
int ntrees; // 木の数
float threshold; // ステージの閾値
};
enum { BOOST = 0 }; // サポートされるステージの種類
// 検出のモード(HaarDetectObjects 関数のパラメータ flags を参照してください)
enum { DO_CANNY_PRUNING = CV_HAAR_DO_CANNY_PRUNING,
SCALE_IMAGE = CV_HAAR_SCALE_IMAGE,
FIND_BIGGEST_OBJECT = CV_HAAR_FIND_BIGGEST_OBJECT,
DO_ROUGH_SEARCH = CV_HAAR_DO_ROUGH_SEARCH };
CascadeClassifier(); // デフォルトコンストラクタ
CascadeClassifier(const string& filename);
~CascadeClassifier(); // デストラクタ
bool empty() const;
bool load(const string& filename);
bool read(const FileNode& node);
void detectMultiScale( const Mat& image, vector<Rect>& objects,
double scaleFactor=1.1, int minNeighbors=3,
int flags=0, Size minSize=Size());
bool setImage( Ptr<FeatureEvaluator>&, const Mat& );
int runAt( Ptr<FeatureEvaluator>&, Point );
bool is_stump_based; // 木が stump の場合は true
int stageType; // ステージの種類(現在は,BOOST のみ)
int featureType; // 特徴量の種類(現在は,HAAR または LBP のどちらか)
int ncategories; // カテゴリ数(カテゴリ特徴量の場合のみ)
Size origWinSize; // 学習画像のサイズ
vector<Stage> stages; // ステージの vector (現在は,BOOST のみ)
vector<DTree> classifiers; // 決定木の vector
vector<DTreeNode> nodes; // 木ノードの vector
vector<float> leaves; // 葉の値の vector
vector<int> subsets; // カテゴリ特徴量によって分けられた部分集合
Ptr<FeatureEvaluator> feval; // 特徴評価器へのポインタ
Ptr<CvHaarClassifierCascade> oldCascade; // pointer to old cascade
};
cv::CascadeClassifier::CascadeClassifier¶
- CascadeClassifier::CascadeClassifier(const string& filename)¶
ファイルから分類器を読み込む.
Parameter: filename – ファイル名.ここから分類器を読み込みます
cv::CascadeClassifier::load¶
- bool CascadeClassifier::load(const string& filename)¶
ファイルから分類器を読み込みます.以前の内容は破棄されます.
Parameter: filename – ファイル名.ここから分類器を読み込みます.ファイルには(haartraining アプリケーションによって学習された)古い haar 分類器,または(traincascade アプリケーションによって学習された)新しいカスケード分類器が保存されている場合があります
cv::CascadeClassifier::read¶
cv::CascadeClassifier::detectMultiScale¶
- void CascadeClassifier::detectMultiScale(const Mat& image, vector<Rect>& objects, double scaleFactor=1.1, int minNeighbors=3, int flags=0, Size minSize=Size())¶
入力画像中から異なるサイズの物体を検出します.検出された物体は,矩形のリストとして返されます.
パラメタ: - image – CV_8U 型の行列.ここに格納されている画像中から物体が検出されます
- objects – 矩形を要素とするベクトル.それぞれの矩形は,検出した物体を含みます
- scaleFactor – 各画像スケールにおける縮小量を表します
- minNeighbors – 物体候補となる矩形は,最低でもこの数だけの近傍矩形を含む必要があります
- flags – このパラメータは,新しいカスケードでは利用されません.古いカスケードに対しては,cvHaarDetectObjects 関数の場合と同じ意味を持ちます
- minSize – 物体が取り得る最小サイズ.これよりも小さい物体は無視されます
cv::CascadeClassifier::setImage¶
- bool CascadeClassifier::setImage(Ptr<FeatureEvaluator>& feval, const Mat& image)¶
画像をセットします(各レベルの画像において detectMultiScale から呼び出されます).
パラメタ: - feval – 特徴量を計算するために用いられる特徴評価器へのポインタ
- image – CV_8UC1 型の行列.ここに格納されている画像中の特徴量が求められます
cv::CascadeClassifier::runAt¶
- int CascadeClassifier::runAt(Ptr<FeatureEvaluator>& feval, Point pt)¶
画像の指定位置で検出器を実行します(検出器の動作対象となる画像は,setImage によってセットされている必要があります).
パラメタ: - feval – 特徴量を計算するために用いられる特徴評価器へのポインタ
- pt – 探索窓の左上角の座標.この探索窓の中の特徴量が計算されます.探索窓のサイズは,学習画像と同じです
以下を返します:
1 - カスケード分類器が,指定位置で物体を検出した場合.
-si - それ以外の場合.si は,与えられた探索窓位置が背景画像であると最初に予測したステージのインデックスです.
cv::groupRectangles¶
- void groupRectangles(vector<Rect>& rectList, int groupThreshold, double eps=0.2)¶
物体候補の矩形をグループ化します..
パラメタ: - rectList – 矩形の入出力ベクトル.出力の場合,グループ化された矩形を格納します
- groupThreshold – 矩形グループにおいて,最低限保持すべき矩形の数 - 1
- eps – 1つのグループにマージするための,矩形端同士の相対的差異
この関数は,汎用関数
partition()
のラッパです.これは,矩形が同一と見なせるかどうかの基準を利用して,すべての入力矩形をクラスタリングします.つまり,同じようなサイズで同じような位置にある(この類似性は
eps
で定義されます)矩形を結合します.
eps=0
の場合,クラスタリングは全く行われません.
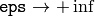 ならば,すべての矩形が1つのクラスタに入れられます.
また,
groupThreshold
個以下の矩形しか含まないような小さいクラスタは,棄却されます.それぞれのクラスタにおいて平均矩形が計算され,出力の矩形リストに書き出されます.
ならば,すべての矩形が1つのクラスタに入れられます.
また,
groupThreshold
個以下の矩形しか含まないような小さいクラスタは,棄却されます.それぞれのクラスタにおいて平均矩形が計算され,出力の矩形リストに書き出されます.
cv::matchTemplate¶
- void matchTemplate(const Mat& image, const Mat& templ, Mat& result, int method)¶
テンプレートと,それに重なった画像領域とを比較します.
パラメタ: - image – テンプレートの探索対象となる画像.8ビットまたは32ビットの浮動小数点型
- templ – 探索されるテンプレート.探索対象となる画像以下のサイズで,同じデータ型でなければいけません
- result – 比較結果のマップ.シングルチャンネル,32ビット,浮動小数点型. image が
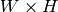 で, templ が
で, templ が 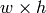 とすると result は
とすると result は 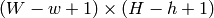 となります
となります - method – 比較手法の指定(以下の説明を参照してください)
この関数は
templ
を
image
全体に対してスライドさせ,それと重なる
の領域とを指定された方法で比較し,その結果を
result
に保存します.以下に,この関数で指定可能な比較手法を表す式を示します(
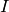 は画像を,
は画像を,
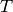 はテンプレートを,
はテンプレートを,
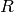 は結果をそれぞれ表します.総和計算は,以下のようにテンプレートと(または)画像領域に対して行われます:
は結果をそれぞれ表します.総和計算は,以下のようにテンプレートと(または)画像領域に対して行われます:
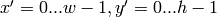
method=CV_TM_SQDIFF
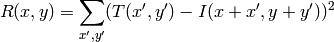
method=CV_TM_SQDIFF_NORMED
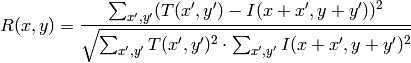
method=CV_TM_CCORR
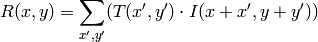
method=CV_TM_CCORR_NORMED
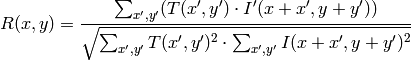
method=CV_TM_CCOEFF
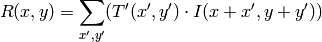
where
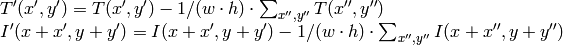
method=CV_TM_CCOEFF_NORMED
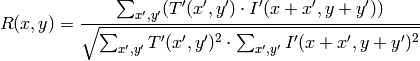
この関数による比較の後,関数 minMaxLoc() を用いて,大域的最小値( CV_TM_SQDIFF の場合)あるいは大域的最大値( CV_TM_CCORR や CV_TM_CCOEFF の場合)を検出することでベストマッチを得ることができます.カラー画像の場合,分母・分子それぞれの総和計算は全てのチャンネルについて行われます(各チャンネルで用いる平均値はそれぞれ異なります).つまり,この関数はカラーテンプレートやカラー画像をとることができます.結果はシングルチャンネル画像のままで,簡単に分析できます.
ヘルプとフィードバック
お探しの情報が見つかりませんか?- FAQ (英語)を試してください.
- ユーザグループ/メーリングリスト (英語)で質問してみてください.
- このドキュメントに誤りなどを見つけたらbug report まで報告してください.また,日本語訳に関する誤りや指摘はopencv.jpまでお願い します.
![]()
目次
- 物体検出
- FeatureEvaluator
- cv::FeatureEvaluator::read
- cv::FeatureEvaluator::clone
- cv::FeatureEvaluator::getFeatureType
- cv::FeatureEvaluator::setImage
- cv::FeatureEvaluator::setWindow
- cv::FeatureEvaluator::calcOrd
- cv::FeatureEvaluator::calcCat
- cv::FeatureEvaluator::create
- CascadeClassifier
- cv::CascadeClassifier::CascadeClassifier
- cv::CascadeClassifier::empty
- cv::CascadeClassifier::load
- cv::CascadeClassifier::read
- cv::CascadeClassifier::detectMultiScale
- cv::CascadeClassifier::setImage
- cv::CascadeClassifier::runAt
- cv::groupRectangles
- cv::matchTemplate