CV リファレンス マニュアル
- 画像処理(Image Processing)
- 勾配,エッジ,コーナー,特徴(Gradients, Edges, Corners and Features)
- サンプリング,補間,幾何変換(Sampling, Interpolation and Geometrical Transforms)
- モルフォロジー演算(Morphological Operations)
- フィルタと色変換(Filters and Color Conversion)
- ピラミッドとその応用(Pyramids and the Applications)
- 画像分割,領域結合,輪郭検出(Image Segmentation, Connected Components and Contour Retrieval)
- 画像と形状のモーメント(Image and Contour Moments)
- 特殊な画像変換(Special Image Transforms)
- ヒストグラム(Histograms)
- マッチング(Matching)
- 構造解析(Structural Analysis)
- モーション解析と物体追跡(Motion Analysis and Object Tracking)
- パターン認識(Pattern Recognition)
- 物体検出(Object Detection)
- カメラキャリブレーションと3次元再構成(Camera Calibration and 3D Reconstruction)
- 参考文献
パターン認識(Pattern Recognition)
物体検出(Object Detection)
ここで述べるオブジェクト検出器は,最初に Paul Viola[Viola01]によって提案され, Rainer Lienhart[Lienhart02]に改良されたもので ある.分類器(つまり,haar-like特徴を用いるブーストされた分類器のカスケー ド)は最初に,数百の正例と負例によって学習される. 正例とは,同一のサイ ズ(例えば,20×20)にスケーリングされた特定のオブジェ クト(つまり,顔 や車)を含むサンプルであり,負例とは,正例と同一サイズの任意の画像であ る.
学習後,分類器は入力画像の(学習に用いられた物と同じサイズの)ROI に対 して適用される.その領域にオブジェクト(顔や車)が写っていると思われる 場合は,分類器は "1" を出力し,それ以外では,"0" を出力する. 画像全体 からオブジェクトを探索するためには,画像中の探索ウィンドウを移 動させな がら,その個々の領域を分類器を用いて判別する.トレーニング時とは異なる 大きさのオブジェクトも検出できるように, 分類器は簡単に 「サイズ変更」 できるように設計される. これは画像自身のサイズを変更するよりも効率的で ある. そして,画像中からサイズが不明なオブジェクトを検出するためには, 異なるスケールで複数回の探索がなされるべきである.
分類器の名前にある「カスケード(cascade)」という単語は,結果として得ら れる分類器がいくつかの単純な分類器(stages)から構成されるという事を意 味する. この単純な分類器は,いずれかのステージでオブジェクト候補が却下 されるか,あるいは全てのステージをパスするまで ROI に対して次々に適用さ れる. また,「ブーストされた(boosted)」という単語は,カスケードの各 ステージにおける分類器自身が複合体である事を意味する.これらは4つの異な るブースティング技法(重み付き投票)のうち 1 つを用いて,基本分類器から 構成される. 現在のところ,Discrete Adaboost,Real Adaboost,Gentle Adaboost そして Logitboost がサポートされる. 基本分類器は,少なくとも 2つの葉を持つ決定木である. Haar-like 特徴は基本分類器の入力であり,後 述のように計算される. 現在のアルゴリズムでは次のような Haar-like 特徴 を用いる.
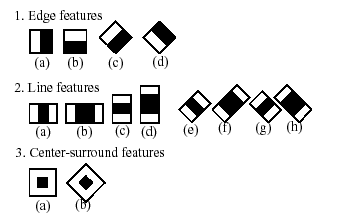
個々の分類器で用いられる特徴は,その形状(1a, 2b など),ROI 内での位置, そしてスケール(このスケールは検出ステージで用いられるスケールとは別物 であるが,これら 2 つのスケールは乗じられる)によって決定される. 例え ばライン特徴の 3 番目(2c)の場合, その応答は,(2 つの白ストライプと 中央の黒ストライプを含む)特徴全体を覆う矩形部分の画像ピクセルの和と, 黒ストライプ部分の画像ピクセルの和を3倍したもの(領域サイズの違いを相殺 するため)との差分として計算される. 矩形領域全体のピクセル値の合計は, インテグラルイメージ(以下とcvIntegralの 項を参照)を用いて高速に計算される.
オブジェクト検出器の動作を知りたい場合は,HaarFaceDetect デモを見ること.
以下のリファレンスでは検出部分のみについて述べる. サンプル集合を用いて ブーストされた分類器のカスケードを学習するための,haartraining と呼ばれ る別のアプリケーションがある. 詳細はopencv/apps/haartraining を参照.
CvHaarFeature, CvHaarClassifier, CvHaarStageClassifier, CvHaarClassifierCascade
ブーストされたHaar分類器構造体
#define CV_HAAR_FEATURE_MAX 3
/* haar 特徴は適切な重みを持つ 2 個,あるいは 3 個の矩形から構成される */
typedef struct CvHaarFeature
{
int tilted; /* 0 は,垂直な特徴,1 は,45度回転した特徴を意味する */
/* 2,3 個の矩形の重みは正負の符号を持ち,その絶対値は矩形の面積に反比例する.
rect[2].weight != 0 の場合,特徴は3個の矩形から構成され,
そうでない場合は2個の矩形から構成される */
struct
{
CvRect r;
float weight;
} rect[CV_HAAR_FEATURE_MAX];
}
CvHaarFeature;
/* 単一決定木による分類器(最も単純な場合は stump).これは個々の画像
位置における特徴に対する応答(つまりウィンドウ内の部分矩形におけるピクセル合計値)
を返し,その応答に依存する値を出力する */
typedef struct CvHaarClassifier
{
int count; /* 決定木のノード数 */
/* これらは,「並列」な配列である.
各インデックスiが決定木のノード(ルートのインデックスは0)に対応する.
left[i] - 左側の子のインデックス(左側の子が葉だった場合には負のインデックス)
right[i] - 右側の子のインデックス(右側の子が葉だった場合には負のインデックス)
threshold[i] - 枝の閾値.特徴応答 <= threshold となる場合は左側の枝が選択され,
そうでない場合は右の枝が選択される.
alpha[i] - 葉に対応する出力値.*/
CvHaarFeature* haar_feature;
float* threshold;
int* left;
int* right;
float* alpha;
}
CvHaarClassifier;
/* ブーストされた分類器の組(= 段階分類器(stage classifiers)):
分類器の応答の合計がthresholdよりも大きい場合には
段階分類器は 1 を返し,そうでない場合は 0 を返す.*/
typedef struct CvHaarStageClassifier
{
int count; /* 組に含まれる分類器の個数 */
float threshold; /* ブーストされた分類器で用いる閾値 */
CvHaarClassifier* classifier; /* 分類器の配列 */
/* これらのフィールドは,単に一直線につながったカスケードよりもむし
ろ,段階分類器の木を構成するために用いられる.*/
int next;
int child;
int parent;
}
CvHaarStageClassifier;
typedef struct CvHidHaarClassifierCascade CvHidHaarClassifierCascade;
/* 段階分類器のカスケードまたは木 */
typedef struct CvHaarClassifierCascade
{
int flags; /* シグネチャ */
int count; /* 段階数 */
CvSize orig_window_size; /* オリジナルのオブジェクトサイズ(カスケードの学習対象)*/
/* これら 2 つのパラメータは cvSetImagesForHaarClassifierCascade によって設定される */
CvSize real_window_size; /* 現在のオブジェクトサイズ */
double scale; /* 現在のスケール */
CvHaarStageClassifier* stage_classifier; /* 段階分類器の配列 */
CvHidHaarClassifierCascade* hid_cascade; /* cvSetImagesForHaarClassifierCascade
によって生成されるカスケードの,
隠れ最適表現 */
}
CvHaarClassifierCascade;
全ての構造体は,ブーストされたHaar分類器のカスケードを表現するために用 いられる.このカスケードは次のような階層構造を持っている.
Cascade:
Stage1:
Classifier11:
Feature11
Classifier12:
Feature12
...
Stage2:
Classifier21:
Feature21
...
...
全ての階層は手動で構成されるか,あるいは関数 cvLoadHaarClassifierCascade や cvLoad を用いてファイルか ら読み込まれる.
cvLoadHaarClassifierCascade
ファイルまたはOpenCV 内に組み込まれた分類器データベースから,学習されたカスケード分類器を読み込む
CvHaarClassifierCascade* cvLoadHaarClassifierCascade(
const char* directory,
CvSize orig_window_size );
- directory
- 学習されたカスケード分類器の記述を含むディレクトリ名.
- orig_window_size
- オブジェクトのオリジナルサイズ(カスケード分類器はこのサイズに合わせて学習される). これはカスケード分類器内に保存されないので,別に指定する必要がある事に注意.
関数 cvLoadHaarClassifierCascade は, ファイルまたは OpenCV 内に組み込まれた分類器データベースから,学習されたHaar分類器のカスケードを読み込む.haartraining アプリケーションを利用して,基本的な学習を行うことができる(詳細は opencv/apps/haartraining を参照).
この関数は,もはやサポートされない.現在では,オブジェクト検出分類器はディレクトリではなく XML/YAML ファイルに保存される. カスケードをファイルから読み込むためには,関数 cvLoad を用いる.
cvReleaseHaarClassifierCascade
haar分類器カスケードを解放する
void cvReleaseHaarClassifierCascade( CvHaarClassifierCascade** cascade );
- cascade
- 解放するカスケード分類器へのポインタのポインタ.ポインタは,この関数によってクリアされる.
関数 cvReleaseHaarClassifierCascade は,手動で作成された,あるいは cvLoadHaarClassifierCascade や cvLoad によって読み込まれたカスケード分類器を解放する.
cvHaarDetectObjects
画像中のオブジェクトを検出
typedef struct CvAvgComp
{
CvRect rect; /* オブジェクトを内包する矩形(グループの平均矩形) */
int neighbors; /* グループ内に存在する隣接矩形の数 */
}
CvAvgComp;
CvSeq* cvHaarDetectObjects( const CvArr* image, CvHaarClassifierCascade* cascade,
CvMemStorage* storage, double scale_factor=1.1,
int min_neighbors=3, int flags=0,
CvSize min_size=cvSize(0,0) );
- image
- この画像の中からオブジェクトを検出する.
- cascade
- Haar 分類器カスケード の内部表現.
- storage
- オブジェクト候補の矩形が得られた場合に,その矩形列を保存するメモリストレージ.
- scale_factor
- スキャン毎に探索ウィンドウがスケーリングされる際のスケールファクタ. 例えばこの値が 1.1 ならば,ウィンドウが 10% 大きくなる.
- min_neighbors
- (これから 1 を引いた値が)オブジェクトを構成する近傍矩形の最小数となる. min_neighbors-1 よりも少ない矩形しか含まないようなグループは全て棄却される. もし min_neighbors が 0 である場合,この関数はグループを一つも生成せず,候補となる矩形を全て返す.これはユーザがカスタマイズしたグループ化処理を適用したい場合に有用である.
- flags
-
処理モード.0 あるいは,以下の値の組み合わせである:
CV_HAAR_SCALE_IMAGE - スケーリングされる度に,関数は, 分類カスケード中の特徴の座標系を 「拡大」するのではなく,逆に画像を縮小する. 現在は,単体でのみ用いることができるオプションである. つまり,このフラグは他のものと併用はできない.
CV_HAAR_DO_CANNY_PRUNING - これがセットされると,関数は Canny エッジ検出器を 非常に多くのエッジを含む(あるいは非常に少ないエッジしか含まない) 画像領域を,探索オブジェクトを含まない領域と見なして棄却する. 顔検出用には特別な閾値が調整されており,この場合,枝刈りにより処理が 高速化される.
CV_HAAR_FIND_BIGGEST_OBJECT - これがセットされると,関数は,(もし存在すれば)画像中の最大のオブジェクトを検出する. つまり,出力シーケンスは一つ(あるいは 0)のエレメントを持つ.
CV_HAAR_DO_ROUGH_SEARCH - CV_HAAR_FIND_BIGGEST_OBJECT がセットされており, min_neighbors > 0 である場合にのみ利用されるべきである. このフラグがセットされると,関数は,現在のスケールにおいて, オブジェクトが検出(かつ,その近傍に充分に候補が検出)された後に, それより小さいサイズの候補を探索しなくなる. min_neighbors が固定されていると, 大抵の場合,このモードは通常のシングルオブジェクトモード (flags=CV_HAAR_FIND_BIGGEST_OBJECT) よりも不正確な(少しだけ大きい)オブジェクト矩形を返す. しかし,このモードはずっと高速であり,最大で10倍程度の速度差になる. 正確さを増すために,min_neighbors に大き な値を指定することができる.シングルオブジェクトモードにおいて,CV_HAAR_DO_CANNY_PRUNING は,たいして処理速度を向上させないばかりか,逆に速度が低下する可能 性もあることに注意する.
- min_size
- 最小ウィンドウサイズ.デフォルトでは分類器の学習に用いられたサンプルのサイズが設定される(顔検出の場合は,~20×20).
関数 cvHaarDetectObjects は, 与えられた画像からオブジェク トを含む様な矩形領域を検出し, それらの領域を矩形の列として返す. この 関数は異なるスケールで画像を複数回スキャンする ( cvSetImagesForHaarClassifierCascade を参照). 毎回,画像中の重なり領域を考慮し, cvRunHaarClassifierCascade を用いて,分類器をその領域に適用する. また調べる領域数を減らすために, Cannyエッジ検出を利用した事前処理(Canny prunning)などの経験則を適用す ることもある. 処理された候補領域(分類器カスケードを通過した領域)が集 められた後, グループ化され,十分に大きいグループの平均矩形のシーケンス が返される. デフォルトパラメータ(scale_factor=1.1, min_neighbors=3, flags=0)は,正確であるが低速なオブジェクト検出用に調整されている. 実際のビデオ画像における,より高速な処理のためには:scale_factor=1.2, min_neighbors=2, flags=CV_HAAR_DO_CANNY_PRUNING, min_size=(例えばビデ オ会議の場合は画像領域の 1/4 から 1/16).
(例)オブジェクト(例えば,顔)を検出するために Haar分類器のカスケードを用いる
#include "cv.h"
#include "highgui.h"
CvHaarClassifierCascade* load_object_detector( const char* cascade_path )
{
return (CvHaarClassifierCascade*)cvLoad( cascade_path );
}
void detect_and_draw_objects( IplImage* image,
CvHaarClassifierCascade* cascade,
int do_pyramids )
{
IplImage* small_image = image;
CvMemStorage* storage = cvCreateMemStorage(0);
CvSeq* faces;
int i, scale = 1;
/* もしフラグが指定された場合,(おそらく)クオリティを落とさずに
ブースティングのパフォーマンスを上げるために入力画像をダウンスケールする.*/
if( do_pyramids )
{
small_image = cvCreateImage( cvSize(image->width/2,image->height/2), IPL_DEPTH_8U, 3 );
cvPyrDown( image, small_image, CV_GAUSSIAN_5x5 );
scale = 2;
}
/* 高速に検出できるように引数を調整 */
faces = cvHaarDetectObjects( small_image, cascade, storage, 1.2, 2, CV_HAAR_DO_CANNY_PRUNING );
/* 全ての矩形を描画する */
for( i = 0; i < faces->total; i++ )
{
/* 矩形だけを取り出す */
CvRect face_rect = *(CvRect*)cvGetSeqElem( faces, i, 0 );
cvRectangle( image, cvPoint(face_rect.x*scale,face_rect.y*scale),
cvPoint((face_rect.x+face_rect.width)*scale,
(face_rect.y+face_rect.height)*scale),
CV_RGB(255,0,0), 3 );
}
if( small_image != image )
cvReleaseImage( &small_image );
cvReleaseMemStorage( &storage );
}
/* 画像ファイル名とカスケードパスをコマンドラインから受け取る */
int main( int argc, char** argv )
{
IplImage* image;
if( argc==3 && (image = cvLoadImage( argv[1], 1 )) != 0 )
{
CvHaarClassifierCascade* cascade = load_object_detector(argv[2]);
detect_and_draw_objects( image, cascade, 1 );
cvNamedWindow( "test", 0 );
cvShowImage( "test", image );
cvWaitKey(0);
cvReleaseHaarClassifierCascade( &cascade );
cvReleaseImage( &image );
}
return 0;
}
cvSetImagesForHaarClassifierCascade
隠れカスケードに画像を割り当てる
void cvSetImagesForHaarClassifierCascade( CvHaarClassifierCascade* cascade,
const CvArr* sum, const CvArr* sqsum,
const CvArr* tilted_sum, double scale );
- cascade
- cvCreateHidHaarClassifierCascade によって作成された隠れHaar分類器カスケード.
- sum
- 32 ビット整数シングルチャンネルのインテグラルイメージ.この 画像は後の2つの画像と同様に,高速な特徴評価と明るさ/コ ントラストの正規化に用いられる. これらの画像は関数 cvIntegral によって,8 ビット整数あるいは 浮動小数点数シングルチャンネルの入力画像から計算できる.
- sqsum
- 64ビット浮動小数点型のシングルチャンネル画像の各ピクセルを 二乗した値に対するインテグラルイメージ.
- tilted_sum
- 32 ビット整数型のシングルチャンネル画像を 45°傾けたものに対するインテグラルイメージ.
- scale
- カスケードのウィンドウスケール. scale=1 の場 合は,オリジナルウィンドウサイズが用いられる(そのサイズの オブジェクトを探す).これは, cvLoadHaarClassifierCascade で指定されたものと同じサイズ ("<default_face_cascade>" の場合は24x24)である. scale=2 の場合,2倍の大きさのウィンドウが用い られる(default face cascade の場合は,48x48). これは探 索を約 4 倍速くする代わりに,48x48 より小さい顔を見つける ことができなくなる.
関数 cvSetImagesForHaarClassifierCascade は,画像かウィン ドウスケール,あるいはその両方を隠れ分類器カスケードに割り当てる.画像 のポインタが NULL だった場合,以前にセットされた画像がさらに用いられる (つまりNULL は 「画像を変更しない」 という事を意味する).スケールパラメータは,このようなデフォルト値をもっていないが,関数 cvGetHaarClassifierCascadeScale を用いて以前の値を取り出し,再利用することができる.この関数は,指定さ れた画像中の指定されたサイズのオブジェクトを検出するカスケードを準備す るために用いられる.この関数は cvHaarDetectObjects によって最初に呼び出されるが, 低レベル関数 cvRunHaarClassifierCascade を使う必要がある場合に,ユーザから呼び出される事もある.
cvRunHaarClassifierCascade
ブーストされた分類器のカスケードを,与えられた画像位置で実行する
int cvRunHaarClassifierCascade( CvHaarClassifierCascade* cascade,
CvPoint pt, int start_stage=0 );
- cascade
- Haar 分類器カスケード.
- pt
- 解析する領域の左上の角.領域のサイズは,オリジナルウィンドウ サイズを ,現在設定されているスケールファクタでスケーリングしたものであ る. 現在のウィンドウサイズは関数 cvGetHaarClassifierCascadeWindowSize を用いて取り出すことができる.
- start_stage
- 0から始まるインデックスで,カスケードステージをどこ から開始するかを決定する.この関数では,それまでの全 ステージを通過している事を仮定している. この機能はプ ロセッサのキャッシュをより効率的に利用するため, cvHaarDetectObjects によって内部的に用いられる.
関数 cvRunHaarHaarClassifierCascade は,Haar分類 器カスケードをある特定の画像位置において動作させる.この関数を使う前に cvSetImagesForHaarClassifierCascade を用いて,インテグラルイメージおよび適切なスケール(=> ウィンドウサ イズ)が設定されるべきである. この関数は,分析対象の領域が全ての分類器 ステージを通過した場合(これは候補の一つになる)には正の値を返し,そう でなければ 0 か負の値を返す.